Курсовая работа: Искусственные нейронные сети
Курсовая работа: Искусственные нейронные сети
Содержание:
Введение
1. Искусственные нейронные сети
1.1 Параллели из биологии
1.2 Определение ИНС
1.3 Архитектура нейронной сети
1.4 Сбор данных для нейронной сети
2 Обучение
2.1 Алгоритм обратного распространения
2.2 Переобучение и обобщение
2.3 Модели теории адаптивного резонанса
3 Многослойный персептрон (MLP)
3.1 Обучение многослойного персептрона
4. Вероятностная нейронная сеть
5. Обобщенно-регрессионная нейронная сеть
6. Линейная сеть
7. Сеть Кохонена
8. Кластеризация
8.1 Оценка качества кластеризации
8.2 Процесс кластеризации
8.3 Применение кластерного анализа
1. Искусственные нейронные сети
Иску́сственные нейро́нные се́ти (ИНС) — математические модели, а также их программные или аппаратные реализации, построенные по принципу организации и функционирования биологических нейронных сетей — сетей нервных клеток живого организма. Это понятие возникло при изучении процессов, протекающих в мозге, и при попытке смоделировать эти процессы. Первой такой попыткой были нейронные сети Маккалока и Питтса. Впоследствии, после разработки алгоритмов обучения, получаемые модели стали использовать в практических целях: в задачах прогнозирования, для распознавания образов, в задачах управления и др.
ИНС представляют собой систему соединённых и взаимодействующих между собой простых процессоров (искусственных нейронов). Такие процессоры обычно довольно просты, особенно в сравнении с процессорами, используемыми в персональных компьютерах. Каждый процессор подобной сети имеет дело только с сигналами, которые он периодически получает, и сигналами, которые он периодически посылает другим процессорам. И тем не менее, будучи соединёнными в достаточно большую сеть с управляемым взаимодействием, такие локально простые процессоры вместе способны выполнять довольно сложные задачи.
С точки зрения машинного обучения, нейронная сеть представляет собой частный случай методов распознавания образов, дискриминантного анализа, методов кластеризации и т. п. С математической точки зрения, обучение нейронных сетей — это многопараметрическая задача нелинейной оптимизации. С точки зрения кибернетики, нейронная сеть используется в задачах адаптивного управления и как алгоритмы для робототехники. С точки зрения развития вычислительной техники и программирования, нейронная сеть — способ решения проблемы эффективного параллелизма. А с точки зрения искусственного интеллекта, ИНС является основой философского течения коннективизма и основным направлением в структурном подходе по изучению возможности построения (моделирования) естественного интеллекта с помощью компьютерных алгоритмов.
Нейронные сети не программируются в привычном смысле этого слова, они обучаются. Возможность обучения — одно из главных преимуществ нейронных сетей перед традиционными алгоритмами. Технически обучение заключается в нахождении коэффициентов связей между нейронами. В процессе обучения нейронная сеть способна выявлять сложные зависимости между входными данными и выходными, а также выполнять обобщение. Это значит, что, в случае успешного обучения, сеть сможет вернуть верный результат на основании данных, которые отсутствовали в обучающей выборке, а также неполных и/или «зашумленных», частично искаженных данных.
1.1 Параллели из биологии
Нейронные сети возникли из исследований в области искусственного интеллекта, а именно, из попыток воспроизвести способность биологических нервных систем обучаться и исправлять ошибки, моделируя низкоуровневую структуру мозга (Patterson, 1996). Основной областью исследований по искусственному интеллекту в 60-е - 80-е годы были экспертные системы. Такие системы основывались на высокоуровневом моделировании процесса мышления (в частности, на представлении, что процесс нашего мышления построен на манипуляциях с символами). Скоро стало ясно, что подобные системы, хотя и могут принести пользу в некоторых областях, не ухватывают некоторые ключевые аспекты человеческого интеллекта. Согласно одной из точек зрения, причина этого состоит в том, что они не в состоянии воспроизвести структуру мозга. Чтобы создать искусственных интеллект, необходимо построить систему с похожей архитектурой.
Мозг состоит из очень большого числа (приблизительно 10,000,000,000) нейронов, соединенных многочисленными связями (в среднем несколько тысяч связей на один нейрон, однако это число может сильно колебаться). Нейроны - это специальная клетки, способные распространять электрохимические сигналы. Нейрон имеет разветвленную структуру ввода информации (дендриты), ядро и разветвляющийся выход (аксон). Аксоны клетки соединяются с дендритами других клеток с помощью синапсов. При активации нейрон посылает электрохимический сигнал по своему аксону. Через синапсы этот сигнал достигает других нейронов, которые могут в свою очередь активироваться. Нейрон активируется тогда, когда суммарный уровень сигналов, пришедших в его ядро из дендритов, превысит определенный уровень (порог активации).
Интенсивность сигнала, получаемого нейроном (а следовательно и возможность его активации), сильно зависит от активности синапсов. Каждый синапс имеет протяженность, и специальные химические вещества передают сигнал вдоль него. Один из самых авторитетных исследователей нейросистем, Дональд Хебб, высказал постулат, что обучение заключается в первую очередь в изменениях "силы" синаптических связей. Например, в классическом опыте Павлова, каждый раз непосредственно перед кормлением собаки звонил колокольчик, и собака быстро научилась связывать звонок колокольчика с пищей. Синаптические связи между участками коры головного мозга, ответственными за слух, и слюнными железами усилились, и при возбуждении коры звуком колокольчика у собаки начиналось слюноотделение.
Таким образом, будучи построен из очень большого числа совсем простых элементов (каждый из которых берет взвешенную сумму входных сигналов и в случае, если суммарный вход превышает определенный уровень, передает дальше двоичный сигнал), мозг способен решать чрезвычайно сложные задачи. Разумеется, мы не затронули здесь многих сложных аспектов устройства мозга, однако интересно то, что искусственные нейронные сети способны достичь замечательных результатов, используя модель, которая ненамного сложнее, чем описанная выше.
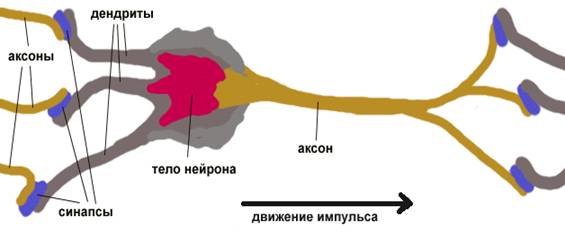
Рис. 1 Нейрон
1.2 Определение ИНС
Искусственная нейронная сеть (ИНС, нейронная сеть) - это набор нейронов, соединенных между собой. Как правило, передаточные функции всех нейронов в нейронной сети фиксированы, а веса являются параметрами нейронной сети и могут изменяться. Некоторые входы нейронов помечены как внешние входы нейронной сети, а некоторые выходы - как внешние выходы нейронной сети. Подавая любые числа на входы нейронной сети, мы получаем какой-то набор чисел на выходах нейронной сети. Таким образом, работа нейронной сети состоит в преобразовании входного вектора в выходной вектор, причем это преобразование задается весами нейронной сети.
Искусственная нейронная сеть это совокупность нейронных элементов и связей между ними.
Основу каждой искусственной нейронной сети составляют относительно простые, в большинстве случаев - однотипные, элементы (ячейки), имитирующие работу нейронов мозга (далее под нейроном мы будем подразумевать искусственный нейрон, ячейку искусственной нейронной сети).
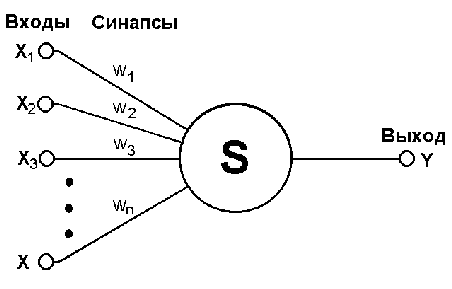
Рис. 2 - Искусственный нейрон
· Нейрон обладает группой синапсов - однонаправленных входных связей, соединенных с выходами других нейронов. Каждый синапс характеризуется величиной синоптической связи или ее весом wi.
· Каждый нейрон имеет текущее состояние, которое обычно определяется, как взвешенная сумма его входов:
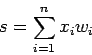
· Нейрон имеет аксон - выходную связь данного нейрона, с которой сигнал (возбуждения или торможения) поступает на синапсы следующих нейронов. Выход нейрона есть функция его состояния:
y = f(s)
Функция f называется функцией активации.
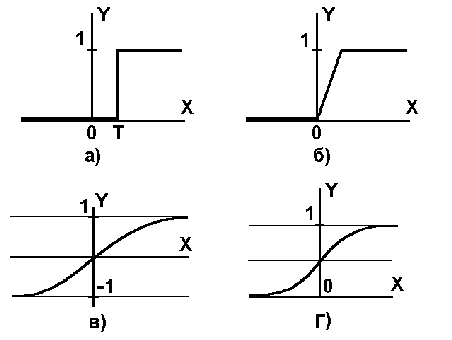
Рис. 3 - Функция активации
Функция активации может иметь разный вид :
· пороговый ( рис. 3.a),
· кусочно-линейный ( рис. 3.б),
· сигмоид( рис. 3.в, 3.г ).
Множество всех нейронов искусственной нейронной сети можно разделить на подмножества - т.н. слои. Взаимодействие нейронов происходит послойно.
Слой искусственной нейронной сети - это множество нейронов на которые в каждый такт времени параллельно поступают сигналы от других нейронов данной сети
Выбор архитектуры искусственной нейронной сети определяется задачей. Для некоторых классов задач уже существуют оптимальные конфигурации. Если же задача не может быть сведена ни к одному из известных классов, разработчику приходится решать задачу синтеза новой конфигурации. Проблема синтеза искусственной нейронной сети сильно зависит от задачи, дать общие подробные рекомендации затруднительно. В большинстве случаев оптимальный вариант искусственной нейронной сети получается опытным путем.
Искусственные нейронные сети могут быть программного и аппаратного исполнения. Реализация аппаратная обычно представляет собой параллельный вычислитель, состоящий из множества простых процессоров.
1.3 Архитектура нейронной сети
ИНС может рассматриваться как направленный граф со взвешенными связями, в котором искусственные нейроны являются узлами. По архитектуре связей ИНС могут быть сгруппированы в два класса (рис. 4): сети прямого распространения, в которых графы не имеют петель, и рекуррентные сети, или сети с обратными связями.
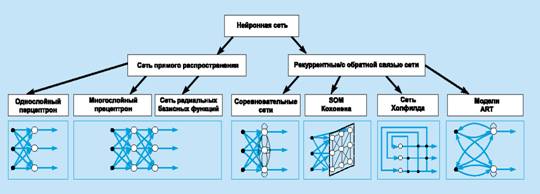
Рис. 4 - архитектуре связей ИНС
В наиболее распространенном семействе сетей первого класса, называемых многослойным перцептроном, нейроны расположены слоями и имеют однонаправленные связи между слоями. На рис. 4 представлены типовые сети каждого класса. Сети прямого распространения являются статическими в том смысле, что на заданный вход они вырабатывают одну совокупность выходных значений, не зависящих от предыдущего состояния сети. Рекуррентные сети являются динамическими, так как в силу обратных связей в них модифицируются входы нейронов, что приводит к изменению состояния сети.
1.4 Сбор данных для нейронной сети
Если задача будет решаться с помощью нейронной сети, то необходимо собрать данные для обучения. Обучающий набор данных представляет собой набор наблюдений, для которых указаны значения входных и выходных переменных. Первый вопрос, который нужно решить, - какие переменные использовать и сколько (и каких) наблюдений собрать.
Выбор переменных (по крайней мере первоначальный) осуществляется интуитивно. Ваш опыт работы в данной предметной области поможет определить, какие переменные являются важными.
Нейронные сети могут работать с числовыми данными, лежащими в определенном ограниченном диапазоне. Это создает проблемы в случаях, когда данные имеют нестандартный масштаб, когда в них имеются пропущенные значения, и когда данные являются нечисловыми.
Более трудной задачей является работа с данными нечислового характера. Чаще всего нечисловые данные бывают представлены в виде номинальных переменных типа Пол = {Муж , Жен }.
Пусть, например, мы хотим научить нейронную сеть оценивать стоимость объектов недвижимости. Цена дома очень сильно зависит от того, в каком районе города он расположен. Город может быть подразделен на несколько десятков районов, имеющих собственные названия, и кажется естественным ввести для обозначения района переменную с номинальными значениями. К сожалению, в этом случае обучить нейронную сеть будет очень трудно, и вместо этого лучше присвоить каждому району определенный рейтинг (основываясь на экспертных оценках).
Нечисловые данные других типов можно либо преобразовать в числовую форму, либо объявить незначащими. Значения дат и времени, если они нужны, можно преобразовать в числовые, вычитая из них начальную дату (время). Обозначения денежных сумм преобразовать совсем несложно. С произвольными текстовыми полями (например, фамилиями людей) работать нельзя и их нужно сделать незначащими.
Вопрос о том, сколько наблюдений нужно иметь для обучения сети, часто оказывается непростым. Известен ряд эвристических правил, увязывающих число необходимых наблюдений с размерами сети (простейшее из них гласит, что число наблюдений должно быть в десять раз больше числа связей в сети). На самом деле это число зависит также от (заранее неизвестной) сложности того отображения, которое нейронная сеть стремится воспроизвести. С ростом количества переменных количество требуемых наблюдений растет нелинейно, так что уже при довольно небольшом (например, пятьдесят) числе переменных может потребоваться огромное число наблюдений. Эта трудность известна как "проклятие размерности", и мы обсудим ее дальше в этой главе.
Для большинства реальных задач бывает достаточно нескольких сотен или тысяч наблюдений. Для особо сложных задач может потребоваться еще большее количество, однако очень редко может встретиться (даже тривиальная) задача, где хватило бы менее сотни наблюдений. Если данных меньше, чем здесь сказано, то на самом деле у Вас недостаточно информации для обучения сети, и лучшее, что Вы можете сделать - это попробовать подогнать к данным некоторую линейную модель.
2. Обучение
Способность к обучению является фундаментальным свойством мозга. В контексте ИНС процесс обучения может рассматриваться как настройка архитектуры сети и весов связей для эффективного выполнения специальной задачи. Обычно нейронная сеть должна настроить веса связей по имеющейся обучающей выборке. Функционирование сети улучшается по мере итеративной настройки весовых коэффициентов. Свойство сети обучаться на примерах делает их более привлекательными по сравнению с системами, которые следуют определенной системе правил функционирования, сформулированной экспертами.
Для конструирования процесса обучения, прежде всего, необходимо иметь модель внешней среды, в которой функционирует нейронная сеть - знать доступную для сети информацию. Эта модель определяет парадигму обучения. Во-вторых, необходимо понять, как модифицировать весовые параметры сети - какие правила обучения управляют процессом настройки. Алгоритм обучения означает процедуру, в которой используются правила обучения для настройки весов.
Существуют три парадигмы обучения: "с учителем", "без учителя" (самообучение) и смешанная. В первом случае нейронная сеть располагает правильными ответами (выходами сети) на каждый входной пример. Веса настраиваются так, чтобы сеть производила ответы как можно более близкие к известным правильным ответам. Усиленный вариант обучения с учителем предполагает, что известна только критическая оценка правильности выхода нейронной сети, но не сами правильные значения выхода. Обучение без учителя не требует знания правильных ответов на каждый пример обучающей выборки. В этом случае раскрывается внутренняя структура данных или Корреляции между образцами в системе данных, что позволяет распределить образцы по категориям. При смешанном обучении часть весов определяется посредством обучения с учителем, в то время как остальная получается с помощью самообучения.
Теория обучения рассматривает три фундаментальных свойства, связанных с обучением по примерам: емкость, сложность образцов и вычислительная сложность. Под емкостью понимается, сколько образцов может запомнить сеть, и какие функции и границы принятия решений могут быть на ней сформированы. Сложность образцов определяет число обучающих примеров, необходимых для достижения способности сети к обобщению. Слишком малое число примеров может вызвать "переобученность" сети, когда она хорошо функционирует на примерах обучающей выборки, но плохо - на тестовых примерах, подчиненных тому же статистическому распределению. Известны 4 основных типа правил обучения: коррекция по ошибке, машина Больцмана, правило Хебба и обучение методом соревнования.
· Правило коррекции по ошибке. При обучении с учителем для каждого входного примера задан желаемый выход d. Реальный выход сети y может не совпадать с желаемым. Принцип коррекции по ошибке при обучении состоит в использовании сигнала (d-y) для модификации весов, обеспечивающей постепенное уменьшение ошибки. Обучение имеет место только в случае, когда перцептрон ошибается. Известны различные модификации этого алгоритма обучения.
· Обучение Больцмана. Представляет собой стохастическое правило обучения, которое следует из информационных теоретических и термодинамических принципов. Целью обучения Больцмана является такая настройка весовых коэффициентов, при которой состояния видимых нейронов удовлетворяют желаемому распределению вероятностей. Обучение Больцмана может рассматриваться как специальный случай коррекции по ошибке, в котором под ошибкой понимается расхождение Корреляций состояний в двух режимах .
· Правило Хебба. Самым старым обучающим правилом является постулат обучения Хебба. Хебб опирался на следующие нейрофизиологические наблюдения: если нейроны с обеих сторон синапса активизируются одновременно и регулярно, то сила синаптической связи возрастает. Важной особенностью этого правила является то, что изменение синаптического веса зависит только от активности нейронов, которые связаны данным синапсом. Это существенно упрощает цепи обучения в реализации VLSI.
· Обучение методом соревнования. В отличие от обучения Хебба, в котором множество выходных нейронов могут возбуждаться одновременно, при соревновательном обучении выходные нейроны соревнуются между собой за активизацию. Это явление известно как правило "победитель берет все". Подобное обучение имеет место в биологических нейронных сетях. Обучение посредством соревнования позволяет кластеризовать входные данные: подобные примеры группируются сетью в соответствии с корреляциями и представляются одним элементом.
При обучении модифицируются только веса "победившего" нейрона. Эффект этого правила достигается за счет такого изменения сохраненного в сети образца (вектора весов связей победившего нейрона), при котором он становится чуть ближе ко входному примеру. На рис. 3 дана геометрическая иллюстрация обучения методом соревнования. Входные векторы нормализованы и представлены точками на поверхности сферы. Векторы весов для трех нейронов инициализированы случайными значениями. Их начальные и конечные значения после обучения отмечены Х на рис. 3а и 3б соответственно. Каждая из трех групп примеров обнаружена одним из выходных нейронов, чей весовой вектор настроился на центр тяжести обнаруженной группы.
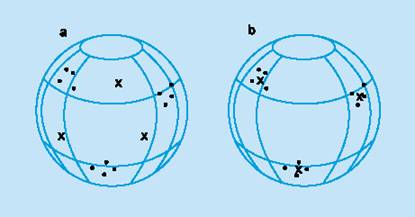
Рис. 5
Пример обучения методом соревнования: (а) перед обучением; (б) после обучения.
Можно заметить, что сеть никогда не перестанет обучаться, если параметр скорости обучения не равен 0. Некоторый входной образец может активизировать другой выходной нейрон на последующих итерациях в процессе обучения. Это ставит вопрос об устойчивости обучающей системы. Система считается устойчивой, если ни один из примеров обучающей выборки не изменяет своей принадлежности к категории после конечного числа итераций обучающего процесса. Один из способов достижения стабильности состоит в постепенном уменьшении до 0 параметра скорости обучения. Однако это искусственное торможение обучения вызывает другую проблему, называемую пластичностью и связанную со способностью к адаптации к новым данным. Эти особенности обучения методом соревнования известны под названием дилеммы стабильности-пластичности.
В Таблице 1 представлены различные алгоритмы обучения и связанные с ними архитектуры сетей (список не является исчерпывающим). В последней колонке перечислены задачи, для которых может быть применен каждый алгоритм. Каждый алгоритм обучения ориентирован на сеть определенной архитектуры и предназначен для ограниченного класса задач. Кроме рассмотренных, следует упомянуть некоторые другие алгоритмы: Adaline и Madaline, линейный дискриминантный анализ, проекции Саммона, анализ главных компонентов.

Таблица 1 - Алгоритмы обучения и связанные с ними архитектуры сетей
2.1 Алгоритм обратного распространения
Самый известный вариант алгоритма обучения нейронной сети - так называемый алгоритм обратного распространения (back propagation). Существуют современные алгоритмы второго порядка, такие как метод сопряженных градиентов и метод Левенберга-Маркара, которые на многих задачах работают существенно быстрее (иногда на порядок). Алгоритм обратного распространения наиболее прост для понимания, а в некоторых случаях он имеет определенные преимущества. Сейчас мы опишем его, а более продвинутые алгоритмы рассмотрим позже. Разработаны также эвристические модификации этого алгоритма, хорошо работающие для определенных классов задач, - быстрое распространение (Fahlman, 1988) и Дельта-дельта с чертой (Jacobs, 1988).
В алгоритме обратного распространения вычисляется вектор градиента поверхности ошибок. Этот вектор указывает направление кратчайшего спуска по поверхности из данной точки, поэтому если мы "немного" продвинемся по нему, ошибка уменьшится. Последовательность таких шагов (замедляющаяся по мере приближения к дну) в конце концов приведет к минимуму того или иного типа. Определенную трудность здесь представляет вопрос о том, какую нужно брать длину шагов.
При большой длине шага сходимость будет более быстрой, но имеется опасность перепрыгнуть через решение или (если поверхность ошибок имеет особо вычурную форму) уйти в неправильном направлении. Классическим примером такого явления при обучении нейронной сети является ситуация, когда алгоритм очень медленно продвигается по узкому оврагу с крутыми склонами, прыгая с одной его стороны на другую. Напротив, при маленьком шаге, вероятно, будет схвачено верное направление, однако при этом потребуется очень много итераций. На практике величина шага берется пропорциональной крутизне склона (так что алгоритм замедляет ход вблизи минимума) с некоторой константой, которая называется скоростью обучения. Правильный выбор скорости обучения зависит от конкретной задачи и обычно осуществляется опытным путем; эта константа может также зависеть от времени, уменьшаясь по мере продвижения алгоритма.
Обычно этот алгоритм видоизменяется таким образом, чтобы включать слагаемое импульса (или инерции). Этот член способствует продвижению в фиксированном направлении, поэтому если было сделано несколько шагов в одном и том же направлении, то алгоритм "увеличивает скорость", что (иногда) позволяет избежать локального минимума, а также быстрее проходить плоские участки.
Таким образом, алгоритм действует итеративно, и его шаги принято называть эпохами. На каждой эпохе на вход сети поочередно подаются все обучающие наблюдения, выходные значения сети сравниваются с целевыми значениями и вычисляется ошибка. Значение ошибки, а также градиента поверхности ошибок используется для корректировки весов, после чего все действия повторяются. Начальная конфигурация сети выбирается случайным образом, и процесс обучения прекращается либо когда пройдено определенное количество эпох, либо когда ошибка достигнет некоторого определенного уровня малости, либо когда ошибка перестанет уменьшаться (пользователь может сам выбрать нужное условие остановки).
2.2 Переобучение и обобщение
Одна из наиболее серьезных трудностей изложенного подхода заключается в том, что таким образом мы минимизируем не ту ошибку, которую на самом деле нужно минимизировать, - ошибку, которую можно ожидать от сети, когда ей будут подаваться совершенно новые наблюдения. Иначе говоря, мы хотели бы, чтобы нейронная сеть обладала способностью обобщать результат на новые наблюдения. В действительности сеть обучается минимизировать ошибку на обучающем множестве, и в отсутствие идеального и бесконечно большого обучающего множества это совсем не то же самое, что минимизировать "настоящую" ошибку на поверхности ошибок в заранее неизвестной модели явления (Bishop, 1995).
Сильнее всего это различие проявляется в проблеме переобучения, или слишком близкой подгонки. Это явление проще будет продемонстрировать не для нейронной сети, а на примере аппроксимации посредством полиномов, - при этом суть явления абсолютно та же.
Полином (или многочлен) - это выражение, содержащее только константы и целые степени независимой переменной. Вот примеры:
y=2x+3
y=3x2+4x+1
Графики полиномов могут иметь различную форму, причем чем выше степень многочлена (и, тем самым, чем больше членов в него входит), тем более сложной может быть эта форма. Если у нас есть некоторые данные, мы можем поставить цель подогнать к ним полиномиальную кривую (модель) и получить таким образом объяснение для имеющейся зависимости. Наши данные могут быть зашумлены, поэтому нельзя считать, что самая лучшая модель задается кривой, которая в точности проходит через все имеющиеся точки. Полином низкого порядка может быть недостаточно гибким средством для аппроксимации данных, в то время как полином высокого порядка может оказаться чересчур гибким, и будет точно следовать данным, принимая при этом замысловатую форму, не имеющую никакого отношения к форме настоящей зависимости (см. рис.).
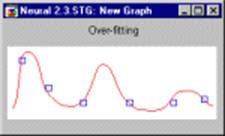
Рис 6 – График полинома
Нейронная сеть сталкивается с точно такой же трудностью. Сети с большим числом весов моделируют более сложные функции и, следовательно, склонны к переобучению. Сеть же с небольшим числом весов может оказаться недостаточно гибкой, чтобы смоделировать имеющуюся зависимость. Например, сеть без промежуточных слоев на самом деле моделирует обычную линейную функцию.
Как же выбрать "правильную" степень сложности для сети? Почти всегда более сложная сеть дает меньшую ошибку, но это может свидетельствовать не о хорошем качестве модели, а о переобучении.
Ответ состоит в том, чтобы использовать механизм контрольной кросс-проверки. Мы резервируем часть обучающих наблюдений и не используем их в обучении по алгоритму обратного распространения. Вместо этого, по мере работы алгоритма, они используются для независимого контроля результата. В самом начале работы ошибка сети на обучающем и контрольном множестве будет одинаковой (если они существенно отличаются, то, вероятно, разбиение всех наблюдений на два множества было неоднородно). По мере того, как сеть обучается, ошибка обучения, естественно, убывает, и, пока обучение уменьшает действительную функцию ошибок, ошибка на контрольном множестве также будет убывать. Если же контрольная ошибка перестала убывать или даже стала расти, это указывает на то, что сеть начала слишком близко аппроксимировать данные и обучение следует остановить. Это явление чересчур точной аппроксимации в процессе обучения и называется переобучением. Если такое случилось, то обычно советуют уменьшить число скрытых элементов и/или слоев, ибо сеть является слишком мощной для данной задачи. Если же сеть, наоборот, была взята недостаточно богатой для того, чтобы моделировать имеющуюся зависимость, то переобучения, скорее всего, не произойдет, и обе ошибки - обучения и проверки - не достигнут достаточного уровня малости.
Описанные проблемы с локальными минимумами и выбором размера сети приводят к тому, что при практической работе с нейронными сетями, как правило, приходится экспериментировать с большим числом различных сетей, порой обучая каждую из них по нескольку раз (чтобы не быть введенным в заблуждение локальными минимумами) и сравнивая полученные результаты. Главным показателем качества результата является здесь контрольная ошибка. При этом, в соответствии с общенаучным принципом, согласно которому при прочих равных следует предпочесть более простую модель, из двух сетей с приблизительно равными ошибками контроля имеет смысл выбрать ту, которая меньше.
Необходимость многократных экспериментов ведет к тому, что контрольное множество начинает играть ключевую роль в выборе модели, то есть становится частью процесса обучения. Тем самым ослабляется его роль как независимого критерия качества модели - при большом числе экспериментов есть риск выбрать "удачную" сеть, дающую хороший результат на контрольном множестве. Для того, чтобы придать окончательной модели должную надежность, часто (по крайней мере, когда объем обучающих данных это позволяет) поступают так: резервируют еще одно - тестовое множество наблюдений. Итоговая модель тестируется на данных из этого множества, чтобы убедиться, что результаты, достигнутые на обучающем и контрольном множествах реальны, а не являются артефактами процесса обучения. Разумеется, для того чтобы хорошо играть свою роль, тестовое множество должно быть использовано только один раз: если его использовать повторно для корректировки процесса обучения, то оно фактически превратится в контрольное множество.
2.3 Модели теории адаптивного резонанса
Напомним, что дилемма стабильности-пластичности является важной особенностью обучения методом соревнования. Как обучать новым явлениям (пластичность) и в то же время сохранить стабильность, чтобы существующие знания не были стерты или разрушены?
Карпентер и Гроссберг, разработавшие модели теории адаптивного резонанса (ART1, ART2 и ARTMAP), сделали попытку решить эту дилемму. Сеть имеет достаточное число выходных элементов, но они не используются до тех пор, пока не возникнет в этом необходимость. Будем говорить, что элемент распределен (не распределен), если он используется (не используется). Обучающий алгоритм корректирует имеющийся прототип категории, только если входной вектор в достаточной степени ему подобен. В этом случае они резонируют. Степень подобия контролируется параметром сходства k, 0<k<1, который связан также с числом категорий. Когда входной вектор недостаточно подобен ни одному существующему прототипу сети, создается новая категория, и с ней связывается нераспределенный элемент со входным вектором в качестве начального значения прототипа. Если не находится нераспределенного элемента, то новый вектор не вызывает реакции сети.
Чтобы проиллюстрировать модель, рассмотрим сеть ART1, которая рассчитана на бинарный (0/1) вход. Упрощенная схема архитектуры ART1 представлена на рис. 7. Она содержит два слоя элементов с полными связями.
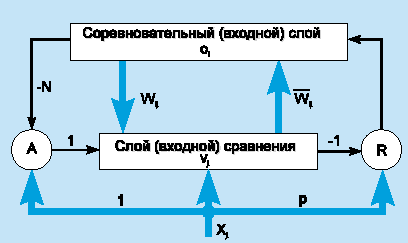
Рис.7 - Архитектура ART1
Направленный сверху вниз весовой вектор wj соответствует элементу j входного слоя, а направленный снизу вверх весовой вектор i связан с выходным элементом i; i является нормализованной версией wi . Векторы wj сохраняют прототипы кластеров. Роль нормализации состоит в том, чтобы предотвратить доминирование векторов с большой длиной над векторами с малой длиной. Сигнал сброса R генерируется только тогда, когда подобие ниже заданного уровня.
Модель ART1 может создать новые категории и отбросить входные примеры, когда сеть исчерпала свою емкость. Однако число обнаруженных сетью категорий чувствительно к параметру сходства.
3. Многослойный персептрон (MLP)
Вероятно, эта архитектура сети используется сейчас наиболее часто. Она была предложена в работе Rumelhart, McClelland (1986) и подробно обсуждается почти во всех учебниках по нейронным сетям. Вкратце этот тип сети был описан выше. Каждый элемент сети строит взвешенную сумму своих входов с поправкой в виде слагаемого и затем пропускает эту величину активации через передаточную функцию, и таким образом получается выходное значение этого элемента. Элементы организованы в послойную топологию с прямой передачей сигнала. Такую сеть легко можно интерпретировать как модель вход-выход, в которой веса и пороговые значения (смещения) являются свободными параметрами модели. Такая сеть может моделировать функцию практически любой степени сложности, причем число слоев и число элементов в каждом слое определяют сложность функции. Определение числа промежуточных слоев и числа элементов в них является важным вопросом при конструировании MLP.
Количество входных и выходных элементов определяется условиями задачи. Сомнения могут возникнуть в отношении того, какие входные значения использовать, а какие нет, - к этому вопросу мы вернемся позже. Сейчас будем предполагать, что входные переменные выбраны интуитивно и что все они являются значимыми. Вопрос же о том, сколько использовать промежуточных слоев и элементов в них, пока совершенно неясен. В качестве начального приближения можно взять один промежуточный слой, а число элементов в нем положить равным полусумме числа входных и выходных элементов. Опять-таки, позже мы обсудим этот вопрос подробнее.
3.1 Обучение многослойного персептрона
После того, как определено число слоев и число элементов в каждом из них, нужно найти значения для весов и порогов сети, которые бы минимизировали ошибку прогноза, выдаваемого сетью. Именно для этого служат алгоритмы обучения. С использованием собранных исторических данных веса и пороговые значения автоматически корректируются с целью минимизировать эту ошибку. По сути, этот процесс представляет собой подгонку модели, которая реализуется сетью, к имеющимся обучающим данным. Ошибка для конкретной конфигурации сети определяется путем прогона через сеть всех имеющихся наблюдений и сравнения реально выдаваемых выходных значений с желаемыми (целевыми) значениями. Все такие разности суммируются в так называемую функцию ошибок, значение которой и есть ошибка сети. В качестве функции ошибок чаще всего берется сумма квадратов ошибок, т.е. когда все ошибки выходных элементов для всех наблюдений возводятся в квадрат и затем суммируются.
В традиционном моделировании (например, линейном моделировании) можно алгоритмически определить конфигурацию модели, дающую абсолютный минимум для указанной ошибки. Цена, которую приходится платить за более широкие (нелинейные) возможности моделирования с помощью нейронных сетей, состоит в том, что, корректируя сеть с целью минимизировать ошибку, мы никогда не можем быть уверены, что нельзя добиться еще меньшей ошибки.
В этих рассмотрениях оказывается очень полезным понятие поверхности ошибок. Каждому из весов и порогов сети (т.е. свободных параметров модели; их общее число обозначим через N) соответствует одно измерение в многомерном пространстве. N+1-е измерение соответствует ошибке сети. Для всевозможных сочетаний весов соответствующую ошибку сети можно изобразить точкой в N+1-мерном пространстве, и все такие точки образуют там некоторую поверхность - поверхность ошибок. Цель обучения нейронной сети состоит в том, чтобы найти на этой многомерной поверхности самую низкую точку.
В случае линейной модели с суммой квадратов в качестве функции ошибок эта поверхность ошибок будет представлять собой параболоид (квадрику) - гладкую поверхность, похожую на часть поверхности сферы, с единственным минимумом. В такой ситуации локализовать этот минимум достаточно просто.
В случае нейронной сети поверхность ошибок имеет гораздо более сложное строение и обладает рядом неприятных свойств, в частности, может иметь локальные минимумы (точки, самые низкие в некоторой своей окрестности, но лежащие выше глобального минимума), плоские участки, седловые точки и длинные узкие овраги.
Аналитическими средствами невозможно определить положение глобального минимума на поверхности ошибок, поэтому обучение нейронной сети по сути дела заключается в исследовании поверхности ошибок. Отталкиваясь от случайной начальной конфигурации весов и порогов (т.е. случайно взятой точки на поверхности ошибок), алгоритм обучения постепенно отыскивает глобальный минимум. Как правило, для этого вычисляется градиент (наклон) поверхности ошибок в данной точке, а затем эта информация используется для продвижения вниз по склону. В конце концов алгоритм останавливается в нижней точке, которая может оказаться всего лишь локальным минимумом (а если повезет - глобальным минимумом).
4. Вероятностная нейронная сеть
Задача оценки плотности вероятности (p.d.f.) по данным имеет давнюю историю в математической статистике и относится к области байесовой статистики. Обычная статистика по заданной модели говорит нам, какова будет вероятность того или иного исхода (например, что на игральной кости шесть очков будет выпадать в среднем одном случае из шести). Байесова статистика переворачивает вопрос вверх ногами: правильность модели оценивается по имеющимся достоверным данным. В более общем плане, байесова статистика дает возможность оценивать плотность вероятности распределений параметров модели по имеющимся данных. Для того, чтобы минимизировать ошибку, выбирается модель с такими параметрами, при которых плотность вероятности будет наибольшей.
При решении задачи классификации можно оценить плотность вероятности для каждого класса, сравнить между собой вероятности принадлежности различным классам и выбрать наиболее вероятный. На самом деле именно это происходит, когда мы обучаем нейронную сеть решать задачу классификации - сеть пытается определить (т.е. аппроксимировать) плотность вероятности.
Традиционный подход к задаче состоит в том, чтобы построить оценку для плотности вероятности по имеющимся данным. Обычно при этом предполагается, что плотность имеет некоторый определенный вид (чаще всего - что она имеет нормальное распределение). После этого оцениваются параметры модели. Нормальное распределение часто используется потому, что тогда параметры модели (среднее и стандартное отклонение) можно оценить аналитически. При этом остается вопрос о том, что предположение о нормальности не всегда оправдано.
Другой подход к оценке плотности вероятности основан на ядерных оценках. Можно рассуждать так: тот факт, что наблюдение расположено в данной точке пространства, свидетельствует о том, что в этой точке имеется некоторая плотность вероятности. Кластеры из близко лежащих точек указывают на то, что в этом месте плотность вероятности большая. Вблизи наблюдения имеется большее доверие к уровню плотности, а по мере отдаления от него доверие убывает и стремится к нулю. В методе ядерных оценок в точке, соответствующей каждому наблюдению, помещается некоторая простая функция, затем все они складываются и в результате получается оценка для общей плотности вероятности. Чаще всего в качестве ядерных функций берутся гауссовы функции (с формой колокола). Если обучающих примеров достаточное количество, то такой метод дает достаточно хорошее приближение к истинной плотности вероятности.
Метод аппроксимации плотности вероятности с помощью ядерных функций во многом похож на метод радиальных базисных функций, и таким образом мы естественно приходим к понятиям вероятностной нейронной сети (PNN) и обобщенно-регрессионной нейронной сети (GRNN). PNN-сети предназначены для задач классификации, а GRNN - для задач регрессии. Сети этих двух типов представляют собой реализацию методов ядерной аппроксимации, оформленных в виде нейронной сети.
Сеть PNN имеет по меньшей мере три слоя: входной, радиальный и выходной. Радиальные элементы берутся по одному на каждое обучающее наблюдение. Каждый из них представляет гауссову функцию с центром в этом наблюдении. Каждому классу соответствует один выходной элемент. Каждый такой элемент соединен со всеми радиальными элементами, относящимися к его классу, а со всеми остальными радиальными элементами он имеет нулевое соединение. Таким образом, выходной элемент просто складывает отклики всех элементов, принадлежащих к его классу. Значения выходных сигналов получаются пропорциональными ядерным оценкам вероятности принадлежности соответствующим классам, и пронормировав их на единицу, мы получаем окончательные оценки вероятности принадлежности классам.
Базовая модель PNN-сети может иметь две модификации.
В первом случае мы предполагаем, что пропорции классов в обучающем множестве соответствуют их пропорциям во всей исследуемой популяции (или так называемым априорным вероятностям). Например, если среди всех людей больными являются 2%, то в обучающем множестве для сети, диагностирующей заболевание, больных должно быть тоже 2%. Если же априорные вероятности будут отличаться от пропорций в обучающей выборке, то сеть будет выдавать неправильный результат. Это можно впоследствии учесть (если стали известны априорные вероятности), вводя поправочные коэффициенты для различных классов.
Второй вариант модификации основан на следующей идее. Любая оценка, выдаваемая сетью, основывается на зашумленных данных и неизбежно будет приводить к отдельным ошибкам классификации (например, у некоторых больных результаты анализов могут быть вполне нормальными). Иногда бывает целесообразно считать, что некоторые виды ошибок обходятся "дороже" других (например, если здоровый человек будет диагностирован как больной, то это вызовет лишние затраты на его обследование, но не создаст угрозы для жизни; если же не будет выявлен действительный больной, то это может привести к смертельному исходу). В такой ситуации те вероятности, которые выдает сеть, следует домножить на коэффициенты потерь, отражающие относительную цену ошибок классификации.
Вероятностная нейронная сеть имеет единственный управляющий параметр обучения, значение которого должно выбираться пользователем, - степень сглаживания (или отклонение гауссовой функции). Как и в случае RBF-сетей, этот параметр выбирается из тех соображений, чтобы шапки " определенное число раз перекрывались": выбор слишком маленьких отклонений приведет к "острым" аппроксимирующим функциям и неспособности сети к обобщению, а при слишком больших отклонениях будут теряться детали. Требуемое значение несложно найти опытным путем, подбирая его так, чтобы контрольная ошибка была как можно меньше. К счастью, PNN-сети не очень чувствительны к выбору параметра сглаживания.
Наиболее важные преимущества PNN-сетей состоят в том, что выходное значение имеет вероятностный смысл (и поэтому его легче интерпретировать), и в том, что сеть быстро обучается. При обучения такой сети время тратится практически только на то, чтобы подавать ей на вход обучающие наблюдения, и сеть работает настолько быстро, насколько это вообще возможно.
Существенным недостатком таких сетей является их объем. PNN-сеть фактически вмещает в себя все обучающие данные, поэтому она требует много памяти и может медленно работать.
PNN-сети особенно полезны при пробных экспериментах (например, когда нужно решить, какие из входных переменных использовать), так как благодаря короткому времени обучения можно быстро проделать большое количество пробных тестов.
5. Обобщенно-регрессионная нейронная сеть
Обобщенно-регрессионная нейронная сеть (GRNN) устроена аналогично вероятностной нейронной сети (PNN), но она предназначена для решения задач регрессии, а не классификации. Как и в случае PNN-сети, в точку расположения каждого обучающего наблюдения помещается гауссова ядерная функция. Мы считаем, что каждое наблюдение свидетельствует о некоторой нашей уверенности в том, что поверхность отклика в данной точке имеет определенную высоту, и эта уверенность убывает при отходе в сторону от точки. GRNN-сеть копирует внутрь себя все обучающие наблюдения и использует их для оценки отклика в произвольной точке. Окончательная выходная оценка сети получается как взвешенное среднее выходов по всем обучающим наблюдениям, где величины весов отражают расстояние от этих наблюдений до той точки, в которой производится оценивание (и, таким образом, более близкие точки вносят больший вклад в оценку).
Первый промежуточный слой сети GRNN состоит из радиальных элементов. Второй промежуточный слой содержит элементы, которые помогают оценить взвешенное среднее. Для этого используется специальная процедура. Каждый выход имеет в этом слое свой элемент, формирующий для него взвешенную сумму. Чтобы получить из взвешенной суммы взвешенное среднее, эту сумму нужно поделить на сумму весовых коэффициентов. Последнюю сумму вычисляет специальный элемент второго слоя. После этого в выходном слое производится собственно деление (с помощью специальных элементов "деления"). Таким образом, число элементов во втором промежуточном слое на единицу больше, чем в выходном слое. Как правило, в задачах регрессии требуется оценить одно выходное значение, и, соответственно, второй промежуточный слой содержит два элемента.
Можно модифицировать GRNN-сеть таким образом, чтобы радиальные элементы соответствовали не отдельным обучающим случаям, а их кластерам. Это уменьшает размеры сети и увеличивает скорость обучения. Центры для таких элементов можно выбирать с помощью любого предназначенного для этой цели алгоритма (выборки из выборки, K-средних или Кохонена), и программа ST Neural Networks соответствующим образом корректирует внутренние веса.
Достоинства и недостатки у сетей GRNN в основном такие же, как и у сетей PNN - единственное различие в том, что GRNN используются в задачах регрессии, а PNN - в задачах классификации. GRNN-сеть обучается почти мгновенно, но может получиться большой и медленной (хотя здесь, в отличие от PNN, не обязательно иметь по одному радиальному элементу на каждый обучающий пример, их число все равно будет большим). Как и сеть RBF, сеть GRNN не обладает способностью экстраполировать данные.
6. Линейная сеть
Согласно общепринятому в науке принципу, если более сложная модель не дает лучших результатов, чем более простая, то из них следует предпочесть вторую. В терминах аппроксимации отображений самой простой моделью будет линейная, в которой подгоночная функция определяется гиперплоскостью. В задаче классификации гиперплоскость размещается таким образом, чтобы она разделяла собой два класа (линейная дискриминантная функция); в задаче регрессии гиперплоскость должна проходить через заданные точки. Линейная модель обычно записывается с помощью матрицы NxN и вектора смещения размера N.
На языке нейронных сетей линейная модель представляется сетью без промежуточных слоев, которая в выходном слое содержит только линейные элементы (то есть элементы с линейной функцией активации). Веса соответствуют элементам матрицы, а пороги - компонентам вектора смещения. Во время работы сеть фактически умножает вектор входов на матрицу весов, а затем к полученному вектору прибавляет вектор смещения.
Линейная сеть является хорошей точкой отсчета для оценки качества построенных Вами нейронных сетей. Может оказаться так, что задачу, считавшуюся очень сложной, можно успешно не только нейронной сетью, но и простым линейным методом. Если же в задаче не так много обучающих данных, то, вероятно, просто нет оснований использовать более сложные модели. В начало
7. Сеть Кохонена
Сети Кохонена принципиально отличаются от всех других типов сетей, в то время как все остальные сети предназначены для задач с управляемым обучением, сети Кохонена главным образом рассчитана на неуправляемое обучение.
При управляемом обучении наблюдения, составляющие обучающие данные, вместе с входными переменными содержат также и соответствующие им выходные значения, и сеть должна восстановить отображение, переводящее первые во вторые. В случае же неуправляемого обучения обучающие данные содержат только значения входных переменных.
На первый взгляд это может показаться странным. Как сеть сможет чему-то научиться, не имея выходных значений? Ответ заключается в том, что сеть Кохонена учится понимать саму структуру данных.
Одно из возможных применений таких сетей - разведочный анализ данных. Сеть Кохонена может распознавать кластеры в данных, а также устанавливать близость классов. Таким образом пользователь может улучшить свое понимание структуры данных, чтобы затем уточнить нейросетевую модель. Если в данных распознаны классы, то их можно обозначить, после чего сеть сможет решать задачи классификации. Сети Кохонена можно использовать и в тех задачах классификации, где классы уже заданы, - тогда преимущество будет в том, что сеть сможет выявить сходство между различными классами.
Другая возможная область применения - обнаружение новых явлений. Сеть Кохонена распознает кластеры в обучающих данных и относит все данные к тем или иным кластерам. Если после этого сеть встретится с набором данных, непохожим ни на один из известных образцов, то она не сможет классифицировать такой набор и тем самым выявит его новизну.
Сеть Кохонена имеет всего два слоя: входной и выходной, составленный из радиальных элементов (выходной слой называют также слоем топологической карты). Элементы топологической карты располагаются в некотором пространстве - как правило двумерном (в пакете ST Neural Networks реализованы также одномерные сети Кохонена).
Обучается сеть Кохонена методом последовательных приближений. Начиная со случайным образом выбранного исходного расположения центров, алгоритм постепенно улучшает его так, чтобы улавливать кластеризацию обучающих данных. В некотором отношении эти действия похожи на алгоритмы выборки из выборки и K-средних, которые используются для размещения центров в сетях RBF и GRNN, и действительно, алгоритм Кохонена можно использовать для размещения центров в сетях этих типов. Однако, данный алгоритм работает и на другом уровне.
Помимо того, что уже сказано, в результате итеративной процедуры обучения сеть организуется таким образом, что элементы, соответствующие центрам, расположенным близко друг от друга в пространстве входов, будут располагаться близко друг от друга и на топологической карте. Топологический слой сети можно представлять себе как двумерную решетку, которую нужно так отобразить в N-мерное пространство входов, чтобы по возможности сохранить исходную структуру данных. Конечно же, при любой попытке представить N-мерное пространство на плоскости будут потеряны многие детали; однако, такой прием иногда полезен, так как он позволяет пользователю визуализировать данные, которые никаким иным способом понять невозможно.
Основной итерационный алгоритм Кохонена последовательно проходит одну за другой ряд эпох, при этом на каждой эпохе он обрабатывает каждый из обучающих примеров, и затем применяет следующий алгоритм:
· Выбрать выигравший нейрон (то есть тот, который расположен ближе всего к входному примеру);
· Скорректировать выигравший нейрон так, чтобы он стал более похож на этот входной пример (взяв взвешенную сумму прежнего центра нейрона и обучающего примера).
В алгоритме при вычислении взвешенной суммы используется постепенно убывающий коэффициент скорости обучения, с тем чтобы на каждой новой эпохе коррекция становилась все более тонкой. В результате положение центра установится в некоторой позиции, которая удовлетворительным образом представляет те наблюдения, для которых данный нейрон оказался выигравшим.
Свойство топологической упорядоченности достигается в алгоритме с помощью дополнительного использования понятия окрестности. Окрестность - это несколько нейронов, окружающих выигравший нейрон. Подобно скорости обучения, размер окрестности убывает со временем, так что вначале к ней принадлежит довольно большое число нейронов (возможно, почти вся топологическая карта); на самых последних этапах окрестность становится нулевой (т.е. состоящей только из самого выигравшего нейрона). На самом деле в алгоритме Кохонена корректировка применяется не только к выигравшему нейрону, но и ко всем нейронам из его текущей окрестности.
Результатом такого изменения окрестностей является то, что изначально довольно большие участки сети "перетягиваются" - и притом заметно - в сторону обучающих примеров. Сеть формирует грубую структуру топологического порядка, при которой похожие наблюдения активируют группы близко лежащих нейронов на топологической карте. С каждой новой эпохой скорость обучения и размер окрестности уменьшаются, тем самым внутри участков карты выявляются все более тонкие различия, что в конце концов приводит к тонкой настройке каждого нейрона. Часто обучение умышленно разбивают на две фазы: более короткую, с большой скоростью обучения и большими окрестностями, и более длинную с малой скоростью обучения и нулевыми или почти нулевыми окрестностями.
После того, как сеть обучена распознаванию структуры данных, ее можно использовать как средство визуализации при анализе данных. Можно также обрабатывать отдельные наблюдения и смотреть, как при этом меняется топологическая карта, - это позволяет понять, имеют ли кластеры какой-то содержательный смысл (как правило при этом приходится возвращаться к содержательному смыслу задачи, чтобы установить, как соотносятся друг с другом кластеры наблюдений). После того, как кластеры выявлены, нейроны топологической карты помечаются содержательными по смыслу метками (в некоторых случаях помечены могут быть и отдельные наблюдения). После того, как топологическая карта в описанном здесь виде построена, на вход сети можно подавать новые наблюдения. Если выигравший при этом нейрон был ранее помечен именем класса, то сеть осуществляет классификацию. В противном случае считается, что сеть не приняла никакого решения.
При решении задач классификации в сетях Кохонена используется так называемый порог доступа. Ввиду того, что в такой сети уровень активации нейрона есть расстояние от него до входного примера, порог доступа играет роль максимального расстояния, на котором происходит распознавание. Если уровень активации выигравшего нейрона превышает это пороговое значение, то сеть считается не принявшей никакого решения. Поэтому, когда все нейроны помечены, а пороги установлены на нужном уровне, сеть Кохонена может служить как детектор новых явлений (она сообщает о непринятии решения только в том случае, если поданный ей на вход случай значительно отличается от всех радиальных элементов).
Идея сети Кохонена возникла по аналогии с некоторыми известными свойствами человеческого мозга. Кора головного мозга представляет собой большой плоский лист (площадью около 0.5 кв.м.; чтобы поместиться в черепе, она свернута складками) с известными топологическими свойствами (например, участок, ответственный за кисть руки, примыкает к участку, ответственному за движения всей руки, и таким образом все изображение человеческого тела непрерывно отображается на эту двумерную поверхность)
8. Кластеризация
Кластеризация предназначена для разбиения совокупности объектов на однородные группы (кластеры или классы). Если данные выборки представить как точки в признаковом пространстве, то задача кластеризации сводится к определению "сгущений точек".
Цель кластеризации - поиск существующих структур.
Кластеризация является описательной процедурой, она не делает никаких статистических выводов, но дает возможность провести разведочный анализ и изучить "структуру данных".
Само понятие "кластер" определено неоднозначно: в каждом исследовании свои "кластеры". Переводится понятие кластер (cluster) как "скопление", "гроздь".
Кластер можно охарактеризовать как группу объектов, имеющих общие свойства.
Характеристиками кластера можно назвать два признака:
· внутренняя однородность;
· внешняя изолированность.
Вопрос, задаваемый аналитиками при решении многих задач, состоит в том, как организовать данные в наглядные структуры, т.е. развернуть таксономии.
Наибольшее применение кластеризация первоначально получила в таких науках как биология, антропология, психология. Для решения экономических задач кластеризация длительное время мало использовалась из-за специфики экономических данных и явлений.
В таблице 2 приведено сравнение некоторых параметров задач классификации и кластеризации.
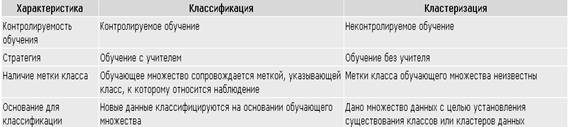
Таблица 2
На рис. 8 схематически представлены задачи классификации и кластеризации.
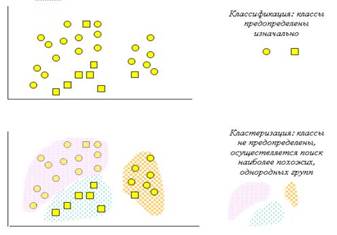
Рис. 8 - Сравнение задач классификации и кластеризации
Кластеры могут быть непересекающимися, или эксклюзивными (non-overlapping, exclusive), и пересекающимися (overlapping) .
Схематическое изображение непересекающихся и пересекающихся кластеров дано на рис. 9.
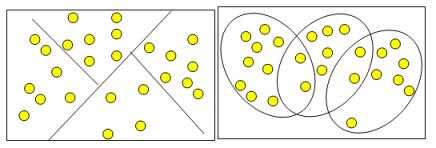
Рис. 9 - Непересекающиеся и пересекающиеся кластеры
Следует отметить, что в результате применения различных методов кластерного анализа могут быть получены кластеры различной формы. Например, возможны кластеры "цепочного" типа, когда кластеры представлены длинными "цепочками", кластеры удлиненной формы и т.д., а некоторые методы могут создавать кластеры произвольной формы.
Различные методы могут стремиться создавать кластеры определенных размеров (например, малых или крупных) либо предполагать в наборе данных наличие кластеров различного размера.
Некоторые методы кластерного анализа особенно чувствительны к шумам или выбросам, другие - менее.
В результате применения различных методов кластеризации могут быть получены неодинаковые результаты, это нормально и является особенностью работы того или иного алгоритма.
Данные особенности следует учитывать при выборе метода кластеризации. На сегодняшний день разработано более сотни различных алгоритмов кластеризации.
Краткая характеристика подходов к кластеризации
· Алгоритмы, основанные на разделении данных (Partitioning algorithms), в т.ч. итеративные:
o разделение объектов на k кластеров;
o итеративное перераспределение объектов для улучшения кластеризации.
· Иерархические алгоритмы (Hierarchy algorithms):
o агломерация: каждый объект первоначально является кластером, кластеры, соединяясь друг с другом, формируют больший кластер и т.д.
· Методы, основанные на концентрации объектов (Density-based methods):
o основаны на возможности соединения объектов;
o игнорируют шумы, нахождение кластеров произвольной формы.
· Грид-методы (Grid-based methods):
o квантование объектов в грид-структуры.
· Модельные методы (Model-based):
o использование модели для нахождения кластеров, наиболее соответствующих данным.
8.1 Оценка качества кластеризации
Оценка качества кластеризации может быть проведена на основе следующих процедур:
· ручная проверка;
· установление контрольных точек и проверка на полученных кластерах;
· определение стабильности кластеризации путем добавления в модель новых переменных;
· создание и сравнение кластеров с использованием различных методов.
Разные методы кластеризации могут создавать разные кластеры, и это является нормальным явлением. Однако создание схожих кластеров различными методами указывает на правильность кластеризации.
8.2 Процесс кластеризации
Процесс кластеризации зависит от выбранного метода и почти всегда является итеративным. Он может стать увлекательным процессом и включать множество экспериментов по выбору разнообразных параметров, например, меры расстояния, типа стандартизации переменных, количества кластеров и т.д. Однако эксперименты не должны быть самоцелью - ведь конечной целью кластеризации является получение содержательных сведений о структуре исследуемых данных. Полученные результаты требуют дальнейшей интерпретации, исследования и изучения свойств и характеристик объектов для возможности точного описания сформированных кластеров.
8.3 Применение кластерного анализа
Кластерный анализ применяется в различных областях. Он полезен, когда нужно классифицировать большое количество информации. Обзор многих опубликованных исследований, проводимых с помощью кластерного анализа, дал Хартиган.
Так, в медицине используется кластеризация заболеваний, лечения заболеваний или их симптомов, а также таксономия пациентов, препаратов и т.д. В археологии устанавливаются таксономии каменных сооружений и древних объектов и т.д. В маркетинге это может быть задача сегментации конкурентов и потребителей. В менеджменте примером задачи кластеризации будет разбиение персонала на различные группы, классификация потребителей и поставщиков, выявление схожих производственных ситуаций, при которых возникает брак. В медицине - классификация симптомов. В социологии задача кластеризации - разбиение респондентов на однородные группы.
Кластерный анализ в маркетинговых исследования
В маркетинговых исследованиях кластерный анализ применяется достаточно широко - как в теоретических исследованиях, так и практикующими маркетологами, решающими проблемы группировки различных объектов. При этом решаются вопросы о группах клиентов, продуктов и т.д.
Так, одной из наиболее важных задач при применении кластерного анализа в маркетинговых исследованиях является анализ поведения потребителя, а именно: группировка потребителей в однородные классы для получения максимально полного представления о поведении клиента из каждой группы и о факторах, влияющих на его поведение.
Важной задачей, которую может решить кластерный анализ, является позиционирование, т.е. определение ниши, в которой следует позиционировать новый продукт, предлагаемый на рынке. В результате применения кластерного анализа строится карта, по которой можно определить уровень конкуренции в различных сегментах рынка и соответствующие характеристики товара для возможности попадания в этот сегмент. С помощью анализа такой карты возможно определение новых, незанятых ниш на рынке, в которых можно предлагать существующие товары или разрабатывать новые.
Кластерный анализ также может быть удобен, например, для анализа клиентов компании. Для этого все клиенты группируются в кластеры, и для каждого кластера вырабатывается индивидуальная политика. Такой подход позволяет существенно сократить объекты анализа, и, в то же время, индивидуально подойти к каждой группе клиентов.
Список литературы
1 http://ru.wikipedia.org/wiki/Нейронная_сеть
2. http://www.statsoft.ru/HOME/TEXTBOOK/modules/stneunet.html
3. http://mechanoid.narod.ru/nns/base/index.html#golovko
4. http://www.scorcher.ru/neuro/science/neurocomp/mem52.htm
5. http://www.neuroproject.ru/neuro.php
6. http://habrahabr.ru/blogs/artificial_intelligence/40659/
7. http://ru.wikipedia.org/wiki/Кластерный_анализ
8. http://www.intuit.ru/department/database/datamining/5/4.html
Перепечатка материалов без ссылки на наш сайт запрещена