Контрольная работа: Формирование и проверка гипотез
Контрольная работа: Формирование и проверка гипотез
Формирование и проверка гипотез
В логике методы рассуждений делятся на два класса: дедуктивные выводы и правдоподобные рассуждения (или недедуктивные выводы). Для выполнения дедуктивных выводов необходимы некоторые правила логического вывода; эти правила определены математической формальной системой, с помощью которой моделируются рассуждения и во многом соответствуют правилам логического вывода, которые используются в строгих математических доказательствах. Из предыдущих разделов мы уже знаем, что для систем логического анализа на основе E-структур предусмотрены два правила вывода – транзитивности и контрапозиции, с помощью которых формируется CT-замыкание структуры. Кроме того, для контроля корректности структуры используются методы проверки наличия или отсутствия коллизий. Эти методы не являются правилами вывода, но способствуют их успешной реализации.
Однако естественные рассуждения не ограничиваются только дедуктивными выводами. Дедукция, как правило, работает на заключительном этапе мыслительных процессов, когда построены некоторые исходные утверждения, которые имеют статус аксиом. Тогда получение следствий (теорем) из аксиом и проверка того, что некоторое утверждение является следствием из этих аксиом, относятся к дедукции В то же время сами аксиомы нередко формируются с помощью некоторых обобщений и творческой интуиции. Эта мыслительная деятельность относится уже к правдоподобным рассуждениям.
Понятно, что с помощью логики, по-видимому, невозможно отобразить все многообразие творческого поиска. Но некоторые его разновидности все же можно воспроизвести, используя строгие математические системы. Некоторые методы правдоподобных рассуждений могут быть реализованы с использованием математики и вполне возможна реализация их на компьютере. К ним относятся индукция (в узком смысле поиск закономерностей на примерах), абдукция (поиск объяснений для некоторых неожиданных и не выводимых из аксиом фактов или примеров) и формирование гипотез (поиск новых утверждений, не являющихся следствиями принятых аксиом).
Примером индукции в рассуждениях является вывод немецким астрономом Иоганном Кеплером (1571–1630) математических законов движения планет вокруг Солнца на основе данных астрономических наблюдений. Но индуктивные выводы не всегда бывают, безусловно, верными. Если мы, допустим, путешествуя по Европе и Азии, встречаем только белых лебедей, то мы можем сделать индуктивный вывод "Все лебеди белые". Но, если мы попадем в Австралию, то нам придется изменить свою точку зрения, так как там встречаются черные лебеди. В настоящее время многие методы поиска закономерностей на примерах развились в целую отрасль компьютерных технологий, которая получила название Data Mining.
Абдукцию мы рассмотрим позже. А в этом разделе познакомимся с гипотезами. По сути гипотеза – это новое знание, которое не является следствием принятых аксиом (или посылок). В то же время, чтобы гипотеза была корректной, она не должна противоречить нашим аксиомам – для E-структур это означает, что при добавлении сформулированной гипотезы в конкретную структуру не происходит логических конфликтов в виде коллизий.
Рассмотрим сначала самые простые случаи такого бесконфликтного обновления знаний. Пусть исходное знание представлено корректной E-структурой R, и в этой E‑структуре имеется множество T базовых терминов. Тогда простейшим случаем бесконфликтного обновления знаний будет случай, когда новое суждение (допустим, это суждение A®B) содержит термины (A и B), которые не входят в состав базовых терминов E‑структуры R. Ясно, что при добавлении этого суждения в R какие-либо коллизии невозможны. Например, если мы к посылкам из примера 6 (раздел 3) добавим суждение "Все лебеди белые", то увидим, что по содержанию оно никак не связано с терминами из этого примера. Суждения такого типа можно считать нейтральными относительно исследуемого знания. И такой случай в силу своей тривиальности никакого интереса не представляет.
Более интересен случай, когда в новом суждении наряду с новыми терминами содержатся базовые термины E-структуры R. Самый простой вариант, когда в систему добавляется новое суждение, но при этом в системе содержится только один из терминов нового суждения. Тогда независимо от того, является ли новым термином предикат или субъект данного суждения, наша система «воспримет» новое суждение без всяких коллизий. За счет постепенного наращивания таких рассмотренных выше случаев происходит неограниченное расширение любой исходной системы.
В качестве примера рассмотрим полисиллогизм Л. Кэрролла.
1) Всякие малые дети неразумны;
2) Все, кто укрощает крокодилов, заслуживают уважения;
3) Все неразумные люди не заслуживают уважения.
Добавим в этот полисиллогизм еще одно суждение: "Все обманщики не заслуживают уважения". В этом суждении предикат представлен термином, уже содержащимся в системе, а субъект – новым термином («обманщики»). В результате такого пополнения наша система также останется корректной системой, а число базовых терминов системы увеличится на два («обманщики» и их отрицание – «не обманщики»). При этом в новой системе появляются некоторые интересные особенности, которые будут рассмотрены несколько позже.
Бесконфликтность системы, обновленной за счет такой гипотезы, можно проверить, построив соответствующее CT‑замыкание. Более сложным является случай, когда в новом суждении предусматривается новая связь между двумя и более терминами исходной системы. Частично этот случай был рассмотрен в предыдущем разделе, когда с помощью верхних конусов в корректной E‑структуре строились некоторые экзистенциальные суждения, в которых появлялись уже новые термины. Тем самым мы бесконфликтно дополняли исходную E-структуру новыми суждениями, не используя при этом основные правила вывода (контрапозиции и транзитивности). Но этот метод позволяет сформировать только гипотезы, которые являются безусловными экзистенциальными суждениями.
Рассмотрим пример условного экзистенциального суждения. Пусть задана простая E‑структура с двумя суждениями: A®B и B®C. Построим ее CT‑замыкание и выделим все максимальные верхние конусы:
AD = {A, B, C}; ![]() D = {
D = {![]() ,
,![]() ,
,![]() }.
}.
CT-замыкание этой E-структуры представлено в виде графа на рис. 1.
дедуктивный логический вывод рассуждение
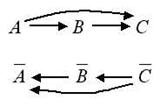
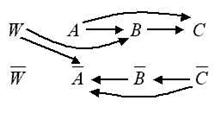
Рис. 1 Рис. 2
Испытаем для
этой E-структуры экзистенциальное суждение W®(![]() , B). Совокупность литералов {
, B). Совокупность литералов {![]() , B} не
включена ни в один из максимальных верхних конусов и поэтому данное суждение не
является безусловным. А будет структура корректной, если мы присоединим это
суждение к исходной системе (рис. 2)?
, B} не
включена ни в один из максимальных верхних конусов и поэтому данное суждение не
является безусловным. А будет структура корректной, если мы присоединим это
суждение к исходной системе (рис. 2)?
Проверка по
теореме показывает, что корректность структуры не нарушится. Но в чем
заключается "условность" данного экзистенциального суждения? Точнее,
при каких условиях или корректных изменениях в структуре добавление этого
суждения в структуру приведет к коллизии? Дело в том, что в структуре
содержится соотношение A®B
(т.е. в терминах алгебры множеств AÍB – нестрогое включение), и при этом допускается
возможность равенства A и B. В то же время экзистенциальное суждение W®(![]() , B) означает, что в множестве B
содержится хотя бы один элемент из дополнения множества A и, следовательно,
равенство A и B невозможно. Другими словами, рассматриваемое экзистенциальное
суждение вводит в структуру ограничение, которое не имело бы места, если бы к
структуре добавлялось безусловное экзистенциальное суждение.
, B) означает, что в множестве B
содержится хотя бы один элемент из дополнения множества A и, следовательно,
равенство A и B невозможно. Другими словами, рассматриваемое экзистенциальное
суждение вводит в структуру ограничение, которое не имело бы места, если бы к
структуре добавлялось безусловное экзистенциальное суждение.
Данный пример иллюстрирует тот факт, что добавление новых суждений, содержащих два и более терминов исходной системы, не всегда является простым делом и порой требует тщательной проверки. Такую проверку можно существенно облегчить, если использовать компьютерную программу анализа рассуждений.
Рассмотрим
ситуацию, когда в новом суждении (или в совокупности новых суждений) содержатся
только базовые термины. Такие суждения не являются экзистенциальными, будем
называть их базовыми суждениями. Начнем с простого примера. Пусть существующее
знание представлено E‑структурой, показанной на рисунке 1. Состав базовых
терминов этой E-структуры образует множество T = {A, B, C, ![]() ,
, ![]() ,
, ![]() }. Спрашивается, можно
ли в эту E-структуру добавить хотя бы одно суждение, используя только термины
из множества T, и при этом нужно проследить, чтобы новое суждение не
содержалось в CT‑замыкании этой структуры?
}. Спрашивается, можно
ли в эту E-структуру добавить хотя бы одно суждение, используя только термины
из множества T, и при этом нужно проследить, чтобы новое суждение не
содержалось в CT‑замыкании этой структуры?
Если не знать некоторых закономерностей E-структур, то для ответа на этот вопрос потребуется тупой перебор всех суждений, не содержащихся в CT-замыкании, и проверка каждого из них на корректность. Возможных вариантов перебора здесь немало, но имеются способы, позволяющие существенно сократить число проверок. Рассмотрим, как это делается. Для решения этой задачи построим таблицу из четырех колонок.

В первой
колонке записывается CT-замыкание нашей системы – слева от стрелки литерал, а
справа – литералы, которые достижимы из этого литерала. Сразу же в этой колонке
видны максимальные элементы нашей структуры – у них скобки справа пустые. Зная
максимальные элементы, можно легко получить минимальные элементы E-структуры
(они необходимы для построения максимальных верхних конусов). Оказывается,
минимальные элементы в E-структурах являются дополнениями максимальных
элементов (имеется доказательство этого соотношения, которое здесь не
приводится). Так, в нашем примере минимальные элементы A и ![]() , поэтому максимальными
элементами будут соответственно
, поэтому максимальными
элементами будут соответственно ![]() и C.
и C.
Во второй
колонке осуществляется преобразование соответствующего исходного суждения CT‑замыкания
так, что в рассматриваемой строке субъект суждения будет тем же самым, а
предикатами суждения будут все термины из T, которые отсутствуют в исходном
суждении. Например, если исходной была строка A®(B, C), то во второй колонке записывается строка A®( A, ![]() ,
,![]() ,
,![]() ), в которой будут все термины из
T, исключая B и C. Очевидно, что суждения, представленные этой строкой (A® A, A®
), в которой будут все термины из
T, исключая B и C. Очевидно, что суждения, представленные этой строкой (A® A, A®![]() , A®
, A®![]() , A®
, A®![]() ), в CT‑замыкании не
содержатся. Некоторые из этих суждений (например, A®
), в CT‑замыкании не
содержатся. Некоторые из этих суждений (например, A®![]() ) можно исключить сразу же без
проверки на корректность.
) можно исключить сразу же без
проверки на корректность.
В третьей
колонке записывается результат, полученный во второй колонке, но при этом из
числа предикатов исключается термин, который в данной строке является
субъектом, и термин, который является отрицанием субъекта. Эти результаты
заносятся в третью колонку таблицы. Таким образом, из возможных кандидатов в
корректные гипотезы сразу же исключаются суждения типа X®X и X®![]() . Первое суждение утверждает, что
каждое множество включено в самого себя, что является аксиомой, а второе
подразумевает элементарную коллизию парадокса и поэтому не является корректным.
. Первое суждение утверждает, что
каждое множество включено в самого себя, что является аксиомой, а второе
подразумевает элементарную коллизию парадокса и поэтому не является корректным.
В четвертой
колонке воспроизводятся записи третьей колонки, но при этом из правой части
этих записей исключаются предикаты, образующие в совокупности с субъектом
суждения, обратные тем, которые содержатся в CT-замыкании. Например, во второй
строке из записи B®(A,![]() ,
,![]() ) мы исключили из правой
части термин A, так как его присутствие подразумевает, что нам придется
проверять суждение B®A,
хотя в CT‑замыкании имеется обратное ему суждение A®B. Как уже известно, совмещение
прямого и обратного суждения в одной E-структуре приводит к появлению
элементарного цикла между двумя литералами.
) мы исключили из правой
части термин A, так как его присутствие подразумевает, что нам придется
проверять суждение B®A,
хотя в CT‑замыкании имеется обратное ему суждение A®B. Как уже известно, совмещение
прямого и обратного суждения в одной E-структуре приводит к появлению
элементарного цикла между двумя литералами.
В результате
оказывается, что предстоит проверить 12 элементарных суждений – по два суждения
в каждой строке. Рассмотрим в качестве примера первую строку A®(![]() ,
,![]() ), в которой содержатся два
элементарных суждения A®
), в которой содержатся два
элементарных суждения A®![]() и A®
и A®![]() . Вначале воспроизведем диаграмму
Хассе нашей исходной системы (рис. 3) и добавим к этой системе первое
проверяемое суждение (рис. 4). Теперь достаточно посмотреть на рисунок, чтобы
убедиться, что новая система содержит коллизию парадокса A®
. Вначале воспроизведем диаграмму
Хассе нашей исходной системы (рис. 3) и добавим к этой системе первое
проверяемое суждение (рис. 4). Теперь достаточно посмотреть на рисунок, чтобы
убедиться, что новая система содержит коллизию парадокса A®![]() , поскольку из A есть путь в
, поскольку из A есть путь в ![]() . Тот же
результат мы получим, если в исходную систему добавим второе проверяемое
суждение (рис. 5).
. Тот же
результат мы получим, если в исходную систему добавим второе проверяемое
суждение (рис. 5).
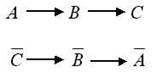
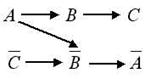
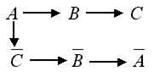
Рис. 3 Рис. 4 Рис. 5
При проверке всех остальных элементарных суждений из четвертой колонки нашей таблицы оказывается, что все они инициируют коллизию парадокса. Таким образом, в исходную систему невозможно добавить какую-либо посылку, содержащую только базовые термины, чтобы при этом не возникало никаких коллизий. Системы с таким свойством мы в дальнейшем будем называть насыщенными системами. При этом "насыщенность" системы не означает, что в нее вообще нельзя ничего добавлять. Как было показано ранее, к указанным системам можно добавлять без коллизий сколько угодно экзистенциальных суждений.
Проверку корректности гипотезы, содержащей только базовые литералы, можно упростить, если воспользоваться соотношением, выраженным следующей теоремой. Но сначала необходимо определить еще одну операцию (инверсию), которая часто используется в E‑структурах .
Инверсией
(Inv(S)) произвольного множества S литералов является множество литералов
такое, что каждому литералу LiÎS ставится в соответствие литерал ![]() Î Inv(S).
Î Inv(S).
Другими
словами, для выполнения инверсии в множестве литералов мы вместо каждого
литерала из этого множества записываем его дополнение. Так, если S = {A, ![]() , C}, то Inv(S)
= {
, C}, то Inv(S)
= {![]() , B,
, B, ![]() }. Инверсия
обладает некоторыми интересными свойствами. В частности, нетрудно проверить, что
при двукратном применении инверсии к определенному множеству литералов будет
получено то же самое множество, т.е. Inv(Inv(S)) = S.
}. Инверсия
обладает некоторыми интересными свойствами. В частности, нетрудно проверить, что
при двукратном применении инверсии к определенному множеству литералов будет
получено то же самое множество, т.е. Inv(Inv(S)) = S.
Теорема. Новое базовое суждение A®B является корректной гипотезой в корректной E‑структуре G, если совместно соблюдаются два равенства:
AÑÇBD = Æ;
AÑÇInv(BD) = Æ.
Доказательство.
Предположим, что AÑÇBD ¹ Æ. Это означает, что существует некоторый литерал W, который
одновременно принадлежит и AÑ, и BD.
Отсюда следует, что W является предшественником литерала A и потомком литерала
B. Поэтому, когда литералы A и B соединяются дугой A®B (т.е. мы добавляем гипотезу в
структуру), то получается, что через литералы A и B существует путь из W в W,
что означает коллизию цикла. Таким образом, необходимость условия (i) доказана.
Предположим, что AÑÇInv(BD) ¹ Æ. Это означает, что существует литерал W, такой, что W
является предшественником A, а ![]() – потомком литерала B. Тогда при
добавлении гипотезы A®B в
структуру появляется путь из W в
– потомком литерала B. Тогда при
добавлении гипотезы A®B в
структуру появляется путь из W в ![]() , что означает коллизию парадокса.
Таким образом, необходимость условия (ii) доказана. Конец доказательства.
, что означает коллизию парадокса.
Таким образом, необходимость условия (ii) доказана. Конец доказательства.
Из доказательства теоремы ясно, что в структуре имеется коллизия цикла в том случае, когда не соблюдается условие (i), а коллизия парадокса, - когда не соблюдается условие (ii).
Рассмотрим,
как можно использовать теорему 5 для решения предыдущей задачи. Предположим,
нам надо проверить корректность гипотезы B®![]() . Строим для этих литералов
соответствующие конусы:
. Строим для этих литералов
соответствующие конусы:
BÑ={A, B}; ![]() D = {
D = {![]() ,
,![]() ,
,![]() }; Inv(
}; Inv(![]() D) = {A, B, C}.
D) = {A, B, C}.
Проверяем
условия теоремы 5: BÑÇ![]() D = Æ; BÑÇ Inv(
D = Æ; BÑÇ Inv(![]() D) = {A, B}.
D) = {A, B}.
Отсюда
следует, что при добавлении гипотезы B®![]() в структуру коллизии цикла не
образуется, зато появляется коллизия парадокса.
в структуру коллизии цикла не
образуется, зато появляется коллизия парадокса.
Проверка насыщенности даже простой системы является весьма трудоемким занятием и здесь целесообразно воспользоваться вычислительными возможностями компьютера. Однако имеются классы E-структур, насыщенность которых легко распознается без нудного перебора. К этому классу относятся, в частности, все E-структуры, у которых диаграмма Хассе содержит две не пересекающиеся друг с другом максимальные цепи, т.е. пути, началом которых являются минимальные элементы структуры. Например, если мы построим диаграмму Хассе какой-то E-структуры и увидим такую картинку (рис. 6), то можем смело без всяких проверок утверждать, что эта система является насыщенной.
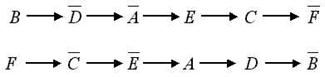
Рис. 6
Нетрудно убедиться, что к данному структурному классу относится также и система, насыщенность которой мы только что проверили методом перебора. К этому классу относятся почти все примеры полисиллогизмов, приводимые в учебниках по логике. Вместе с тем, этот класс является всего лишь частным случаем E‑структур и соответствующих им рассуждений, т.е. возможны классы E-структур, у которых схемы будут более запутанными. Далее будут рассмотрены E‑структуры, для которых проверка насыщенности не является такой простой процедурой. Приведем определения и соотношения, которые после предшествовавшего анализа будут более понятными.
Для заданной E-структуры любое суждение, содержащее только пару различных базовых терминов этой E-структуры и не содержащееся в ее CT-замыкании, называется базовым невыводимым суждением.
E-структура является насыщенной, если добавление в нее любого базового невыводимого суждения вызывает коллизии парадокса или цикла. В противном случае такая структура является ненасыщенной.
Для ненасыщенных E-структур любое ее базовое невыводимое суждение, не вызывающее в этой E-структуре каких-либо коллизий, называется базовой корректной гипотезой этой E-структуры.
Перепечатка материалов без ссылки на наш сайт запрещена