Курсовая работа: Побудова залежності між метриками та експертною оцінкою программного забезпечення
Курсовая работа: Побудова залежності між метриками та експертною оцінкою программного забезпечення
Зміст
Завдання
1. Призначення, описання й характеристики властивості ПЗ та метрик, які будуть досліджуватися
2. Описання алгоритму та засобів, які будуть використовуватися
3. Первинний статистичний аналіз із гістограмами метрик, експертної оцінки властивості ПЗ та основними статистичними характеристиками, та перевірками
4. Висновки по первинному статистичному аналізу
5. Кореляційний аналіз з кореляційними полями та розрахованими коефіцієнтами кореляції, та перевірками
6. Висновки по кореляційному аналізу
7. Регресійний аналіз з побудованими лініями регресій, визначеними функціями регресій, коефіцієнтами у функціях та перевірками
8. Висновки по регресійному аналізу
9. Загальні висновки
Завдання
Побудувати залежності між метриками ПЗ та експертною оцінкою властивості ПЗ. Метрики та властивості використати згідно індивідуального варіанту.
Побудова залежності між метриками та експертною оцінкою включає побудову залежностей між прямими метриками та експертною оцінкою, непрямими метриками та експертною оцінкою.
Значення експертних оцінок отримати з лабораторної роботи № 5, значення метрик (прямих та непрямих) отримати з лабораторної роботи № 6. Метрики та експертні оцінки повинні бути отримані для одних і тих самих проектів. Для достовірності отриманих даних по кожній метриці повинно бути отримано не менше 2000 значень (з лабораторної роботи № 6), експертних оцінок – не менше 15-и. Залежності будувати між 5-ма прямими метриками та експертною оцінкою, 5-ма непрямими метриками та експертною оцінкою (використати метрики з лабораторної роботи № 6).
Отримані результати по залежностях між метриками та експертними оцінками порівняти із результатами побудови залежностей між прямими та непрямими метриками в лабораторних роботах № 4 та 5. Визначити чи мають спільні тенденції залежності між тими прямими метриками та експертними оцінками, непрямими метриками та експертними оцінками, які мають залежності між собою (прямі-непрямі метрики). Пояснити чому.
Варіант 13
| Зрозумілість інтерфейсу, Ефективність | CYC, NOP, HIT, FOUT, NOC | AMW, ATFD, BovR, CC, CDISP |
1. Призначення, описання й характеристики властивості ПЗ та метрик, які будуть досліджуватися
При виконанні курсової роботи будуть досліджуватись наступні характеристики властивостей ПЗ:
- Зрозумілість інтерфейсу - чи є призначений для користувача інтерфейс інтуїтивно зрозумілим?
- Ефективність - наскільки раціонально програма використовує ресурси (пам'ять, процесор) при виконанні своїх завдань
Значення експертних оцінок характеристик властивостей ПЗ по проектах приведено в таблиці 1(оцінки, які були зроблені мною для трьох проектів). Всі інші оцінки , які були зроблені підгрупою для трьох проектів подано в документі формату Excel «Метрики програмних продуктів.xclx».
Таблиця 1. Значення експертних оцінок
| № п.п. | Властивість | Оцінка (0..10) | Пояснення |
| Talend Open Studio 3.2.1 | |||
| 1. | Ефективність | 8 | При виконанні поставлених завдань, програма потребує мінімальну кількість оперативної памяті та інших ресурсів для роботи без затримки |
| 2. | Зрозумілість інтерфейсу | 9 | Інтерфейс користувача є інтуїтивно зрозумілим, тому не потрібно дуже часто звертатись до документації з метою отриманні допомоги у реалізації тієї чи іншої функції |
| Openproj-1.4-src | |||
| 1. | Ефективність | 9 | Пам’ять раціонально розподілена для усієї програми, що дає змогу раціонально використовувати ресурси при виконанні завдань. Але, як вже уточнювалось раніше, у програмному коді є частина коду, яка не якісно використовує пам’ять. |
| 2. | Зрозумілість інтерфейсу | 10 | Інтерфейс користувача інтуїтивно зрозумілий та зручний у використанні. Тобто для користуванням даними програмним забезпеченням не треба отримувати додаткових знань |
| plazma-source 0.1.8 | |||
| 1. | Ефективність | 8 | При роботі програми не потрібне використання великої кількості оперативної памяті. |
| 2. | Зрозумілість інтерфейсу | 10 | Інтерфейс користувача є інтуїтивно зрозумілим. Оскільки він відповідає стандарту інтерфейсів IBM 1991. |
Також будуть досліджені наступні метрики програмного забезпечення, які подано в таблиці 2(прямі метрики) та таблиці 3(непрямі метрики).
Таблиця 2. Прямі метрики
| Метрика | Короткий опис |
| CYCLO | Цикломатична складність програмного коду |
| NOC | Загальна кількість класів в проекті |
| NOP | Загальна кількість параметрів в програмному коді |
| HIT | Глибина дерева успадкування |
| FOUT | Кількість модулів, що звертаються до інших модулів |
Таблиця 3. Непрямі метрики
| Метрика | Короткий опис |
| AMW | Середня вага методу |
| ATFD | Доступ до зовнішніх даних |
| BОvR | Співвідношення перевизначених базових класів |
| CC | Зміна класів |
| CDISP | Дисперсійний зв'язок |
Результати вимірювань метрик програмних продуктів, що були вище зазначені, подано в документі формату Excel «Метрики програмних продуктів.xclx», що є додатком до даної курсової роботи.
При виконанні даної курсової роботи були використані наступні програмні засоби:
- iPlasma – дає можливість отримати значення 80-х об’єктно-орієнтованих метрик. Функціонально повний засіб для вимірювання, який вимірює метрики, які відносяться як до окремих класів, методів та пакетів, так і для проекту в цілому. Крім того, метрики виводяться не тільки в числовому вигляді, а й у графічному – у вигляді гістограми.
- Statistica – пакет для всебічного статистичного аналізу, розроблений компанією StatSoft. У пакеті STATISTICA реалізовані процедури для аналізу даних (data analysis), управління даними (data management), видобутку даних (data mining), візуалізації даних (data visualization).
2. Описання алгоритму та засобів, які будуть використовуватися
При виконанні даної курсової роботи буде проводитись статистичний аналіз.
Статистичний аналіз, який виконується з метою визначення залежностей між метриками, складається з трьох етапів: первинний статистичний аналіз, кореляційний аналіз та регресійний аналіз.
Схема побудови залежностей між метриками представлена на рис. 1.

Рис. 1 Схема побудови залежностей
Первинний статистичний аналіз метрик та експертних оцінок
Метою первинного статистичного аналізу являється визначення закону розподілу випадкової величини, точніше визначення відповіді на питання „Чи є даний закон розподілу випадкової величини нормальним?”. На етапі первинного статистичного аналізу відбувається дослідження вхідних статистичних даних. Спочатку аналізуються метрики, отримані в результаті вимірювання набору програм, далі експертні оцінки, що зробили експерти для цього ж набору програм.
Кінцевою метою первинного статистичного аналізу є визначення, чи належить побудований закон до нормального. Причиною цього є те, що подальший аналіз базується на перевірці на „нормальність” закону розподілу, тобто кожний з наступних етапів починається цією перевіркою, і в залежності від відповіді застосовуються різні методи обчислень.
Кореляційний аналіз пар „метрика – експертна оцінка”
На етапі кореляційного аналізу визначається, чи існує залежність між певними метриками та експертними оцінками, чи її немає. Якщо залежність існує, то проводиться первинна обробка даних для визначення довірчої ймовірності та виду залежності. В іншому випадку робиться висновок про відсутність залежності.
Отже, результатом даного етапу є відсіювання незалежних між собою пар „метрика – експертна оцінка” та визначення за можливістю виду залежності для інших пар.
Регресійний аналіз залежних величин
Регресійний аналіз – останній етап в дослідженні на залежність метрик та експертних оцінок. Він проводиться тільки при виконанні умови, що дисперсія залежної змінної (експертної оцінки) повинна залишатися постійною при зміні значення аргументу (метрики), тобто, спочатку визначається дисперсія експертної оцінки для кожного прийнятого значення метрики.
Якщо пара „метрика – експертна оцінка” пройшла всі етапи і не була відсіяною, робиться висновок, що експертна оцінка залежить певним чином від значення метрики з силою, що показує коефіцієнт детермінації, а вигляд залежності визначає лінія регресії.
3. Первинний статистичний аналіз із гістограмами метрик, експертної оцінки властивості ПЗ та основними статистичними характеристиками, та перевірками
Первинний статистичний аналіз проводиться за допомогою програми Statistica, що набагато спрощує обчислення.
Важливим способом "опису" змінної є форма її розподілу, яка показує, з якою частотою значення змінної потрапляють в певні інтервали. Ці інтервали, що називаються інтервалами угруповання, обираються дослідником. Зазвичай дослідника цікавить, наскільки точно розподіл можна апроксимувати нормальним (див. нижче картинку з прикладом такого розподілу) (див. також Елементарні поняття статистики). Прості описові статистики дають про це деяку інформацію. Наприклад, якщо асиметрія (показує відхилення розподілу від симетричного) істотно відрізняється від 0, то розподіл несиметрично, у той час як нормальний розподіл абсолютно симетрично. Отже, у симетричного розподілу асиметрія дорівнює 0. Асиметрія розподілу з довгим правим хвостом позитивна. Якщо розподіл має довгий лівий хвіст, то його асиметрія негативна. Далі, якщо ексцес (показує "гостроту піку" розподілу) істотно відрізняється від 0, то розподіл має або більше закруглений пік, ніж нормальне, або, навпаки, має більш гострий пік (можливо, є декілька піків). Зазвичай, якщо ексцес позитивний, то пік загострений, якщо негативний, то пік закруглений. Ексцес нормального розподілу дорівнює 0.
Більш точну інформацію про форму розподілу можна отримати за допомогою критеріїв нормальності (наприклад, критерію Колмогорова-Смирнова або W критерію Шапіро-Уїлки). Однак жоден із цих критеріїв не може замінити візуальну перевірку за допомогою гістограми (графіка, що показує частоту влучень значень змінної в окремі інтервали).
Гістограма дозволяє "на око" оцінити нормальність емпіричного розподілу. На гістограму також накладається крива нормального розподілу. Гістограма дозволяє якісно оцінити різні характеристики розподілу. Наприклад, на ній можна побачити, що розподіл бімодальному (має 2 піку). Це може бути викликано, наприклад, тим, що вибірка неоднорідна, можливо, витягли з двох різних популяцій, кожна з яких більш-менш нормальна. У таких ситуаціях, щоб зрозуміти природу спостережуваних змінних, можна спробувати знайти якісний спосіб поділу вибірки на дві частини.
Кінцевою метою первинного статистичного аналізу є визначення, чи належить побудований закон до нормального. Причиною цього є те, що подальший аналіз базується на перевірці на „нормальність” закону розподілу, тобто кожний з наступних етапів починається цією перевіркою, і в залежності від відповіді застосовуються різні методи обчислень.
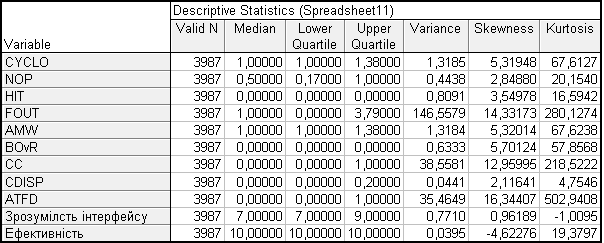
Статистичні дані, які були виміряні за допомогою програмного забезпечення Statistica подано в таблиці 4.
Таблиця 4. Статистичні дані
Нижче на малюнках подано побудовані гістограми по кожній метриці
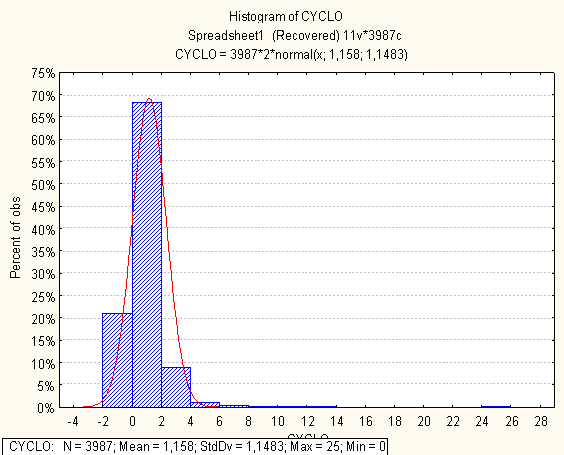
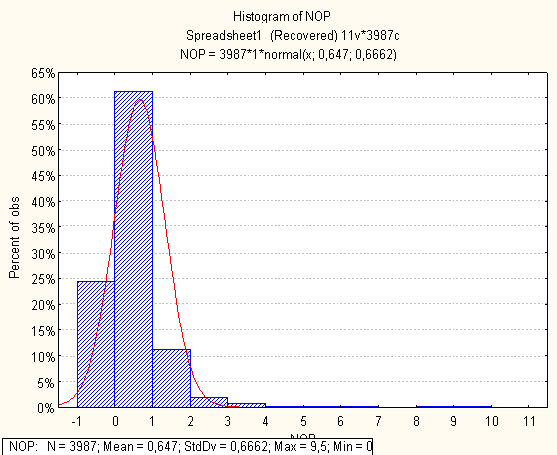
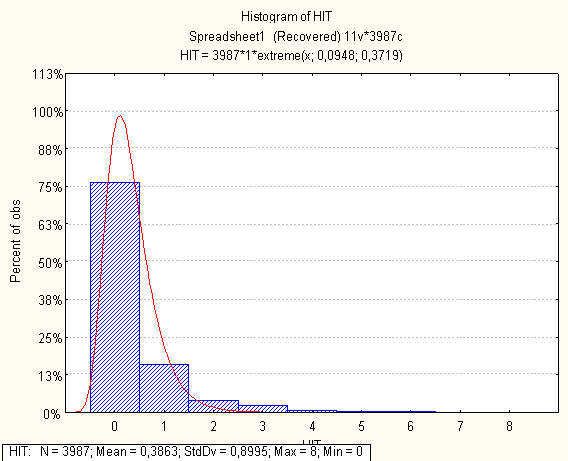
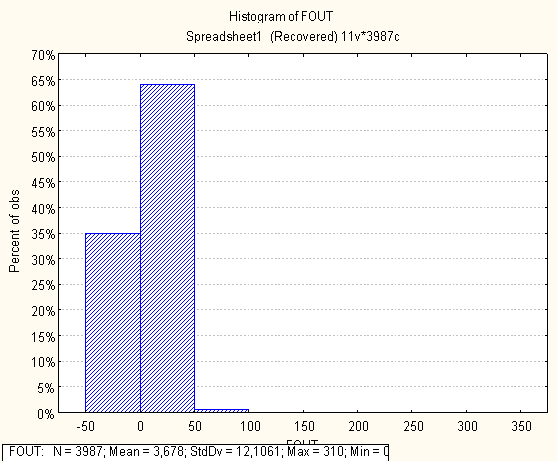
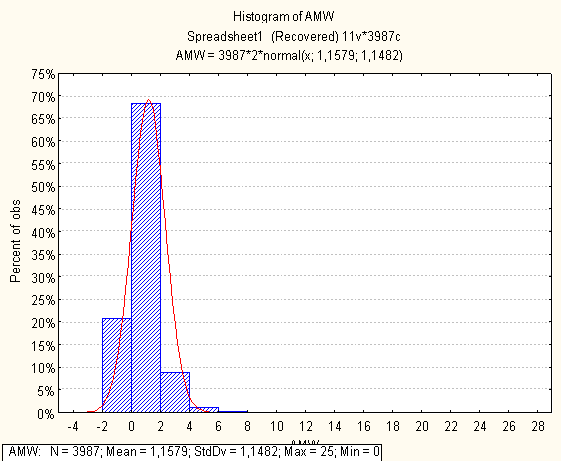

4. Висновки по первинному статистичному аналізі
При проведенні первинного статистичного аналізу було обчислено статичні характеристики такі, як математичне сподівання, середнє квадратичне відхилення, коефіцієнт ексцесу та асиметрії, довірчі інтервали та визначено закони розподілу.
У відповідності до отриманих даних можна зробити наступні висновки:
Метрики з нормальним розподілом
- CYCLO
- NOP
- FOUT
- AMW
- Ефективність(експертна оцінка)
Метрики з ненормальним розподілом
- HIT
- BOvR
- CC
- CDISP
- ATFD
- Зрозумілість інтерфейсу(експертна оцінка)
Ці дані будуть в подальшому використовуватись для кореляційного та регресійного аналізу.
5. Кореляційний аналіз з кореляційними полями та розрахованими коефіцієнтами кореляції, та перевірками
Визначення кореляції. Кореляція являє собою міру залежності змінних. Найбільш відома кореляція Пірсона. При обчисленні кореляції Пірсона передбачається, що змінні виміряні, як мінімум, у інтервального шкалою. Деякі інші коефіцієнти кореляції можуть бути обчислені для менш інформативних шкал. Коефіцієнти кореляції змінюються в межах від -1.00 до +1.00. Зверніть увагу на крайні значення коефіцієнта кореляції. Значення -1.00 означає, що змінні мають строгу негативну кореляцію. Значення +1.00 означає, що змінні мають строгу позитивну кореляцію. Відзначимо, що значення 0.00 означає відсутність кореляції.
Негативна кореляція. Дві змінні можуть бути пов'язані таким чином, що при зростанні значень однієї з них значення іншої зменшуються. Це і показує негативний коефіцієнт кореляції. Про такі змінні говорять, що вони негативно корельовані.
Позитивна кореляція. Зв'язок між двома змінними може бути такою - коли значення однієї змінної зростають, значення іншої змінної також зростають. Це і показує позитивний коефіцієнт кореляції. Про такі змінні говорять, що вони позитивно корельовані.
Найбільш часто використовуваний коефіцієнт кореляції Пірсона r називається також лінійної кореляцією, тому що вимірює ступінь лінійних зв'язків між змінними.
Проста лінійна кореляція (Пірсона r). Кореляція Пірсона (далі називана просто кореляцією) припускає, що дві розглянуті перемінні виміряні в інтервальній шкалі. Вона визначає ступінь, з якою значення двох змінних "пропорційні" один одному. Важливо, що значення коефіцієнта кореляції не залежить від масштабу виміру. Наприклад, кореляція між ростом і вагою буде однієї і тієї ж, незалежно від того, проводилися виміри в дюймах і чи фунтах у сантиметрах і кілограмах. Пропорційність означає просто лінійну залежність. Кореляція висока, якщо на графіку залежність "можна представити" прямою лінією (з позитивним чи негативним кутом нахилу).
Помилкові кореляції. Грунтуючись на коефіцієнтах кореляції, ви не можете строго довести причинного залежності між змінними , однак можете визначити помилкові кореляції, тобто кореляції, які обумовлені впливами "інших", що залишаються за межами вашого поля зору змінних. Найкраще зрозуміти помилкові кореляції на простому прикладі. Відомо, що існує кореляція між шкодою, завданою пожежею, і кількістю пожежних, почали гасити пожежу. Однак ця кореляція нічого не говорить про те, наскільки зменшаться втрати, якщо буде викликано менше число пожежних. Причина в тому, що є третя змінна яка впливає як на заподіяний збиток, так і на число викликаних пожежників. Якщо ви будете "контролювати" цю змінну, то вихідна кореляція або зникне, або, можливо, навіть змінить свій знак. Основна проблема хибної кореляції полягає в тому, що ви не знаєте, хто є її агентом. Тим не менше, якщо ви знаєте, де шукати, то можна скористатися приватні кореляції, щоб контролювати (частково виключена) вплив певних змінних.
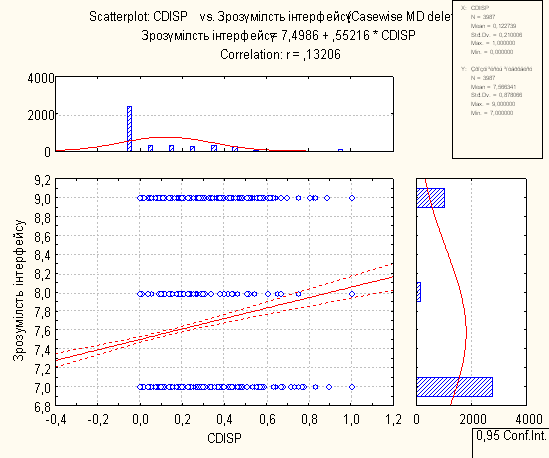
Кореляційний аналіз проводився за допомогою пакету Statistica. Отримані результати по кореляційному аналізу подано в таблиці 4.
Таблиця 5. Результати кореляційного аналізу для пар прямі метрики-експертні оцінки, непрямі метрики-експертні оцінки
6. Висновки по кореліційному аналізу
При проведенні кореляційного аналізу було за допомогою пакету Statistica обчислено коефіцієнти для пар метрика-експертна оцінка.
На основі отриманих даних, які подані в таблиці 4, можна зробити наступні висновки:
- Значення коефіцієнтів кореляції для пар «метрика-експертна оцінка», що зображені червоним кольором вказують на залежність між метриками та експертною оцінкою
- Значення коефіцієнтів кореляції для пар «метрика-експертна оцінка», що зображені чорним кольором не залежні між собою
- Коефіцієнти кореляції не є дуже великим, що дає змогу сказати, що залежність між метриками та експертними оцінками, які досліджуються в данії курсовій роботі, не є значною.
Дані, що були отримані при проведені кореляційного аналізу, будуть використані з метою проведення регресійного аналізу.
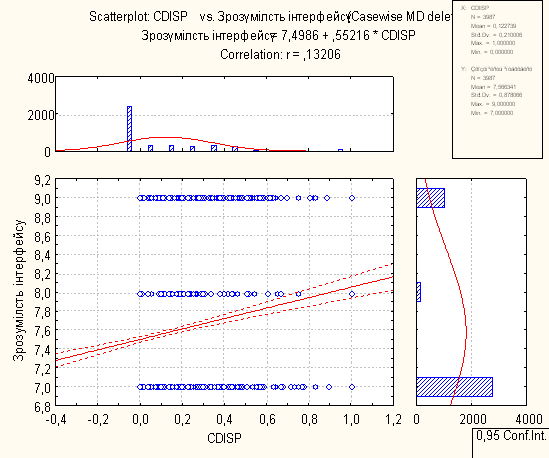
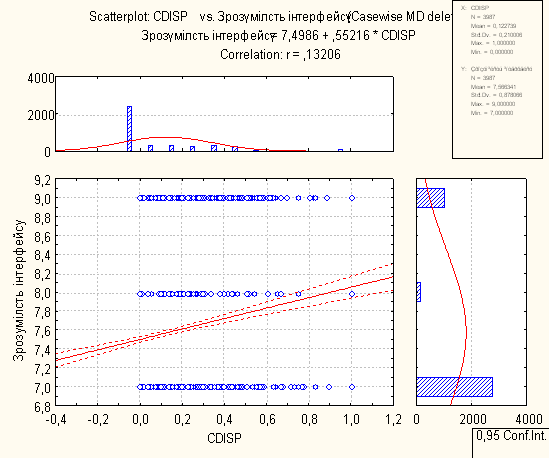
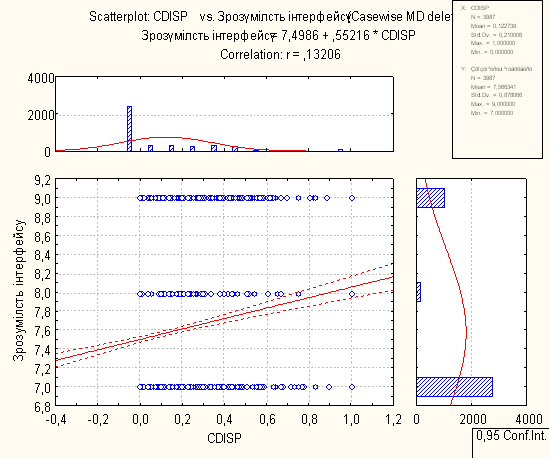
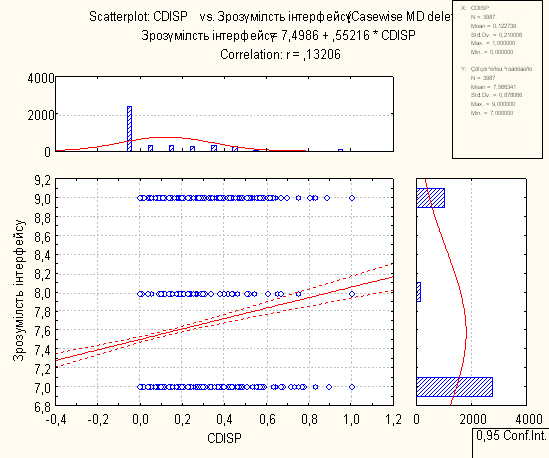
7. Регресійний аналіз з побудованими лініями регресій, визначеними функціями регресій, коефіцієнтами у функціях та перевірками
Загальне призначення множинної регресії (цей термін був вперше використаний в роботі Пірсона - Pearson, 1908) полягає в аналізі зв'язку між кількома незалежними змінними (званими також регрессорамі або предикторами) і залежною змінною. Наприклад, агент з продажу нерухомості міг би вносити в кожен елемент реєстру розмір будинку (у квадратних футів), кількість спалень, середній дохід населення в цьому районі відповідно до даних перепису і суб'єктивну оцінку привабливості будинку. Як тільки ця інформація зібрана для різних будинків, було б цікаво подивитися, чи пов'язані і яким чином ці характеристики будинку з ціною, за якою він був проданий. Наприклад, могло б виявитися, що кількість спальних кімнат є кращим пророкує фактором (предиктором) для ціни продажу будинку в деякому специфічному районі, ніж "привабливість" будинку (суб'єктивна оцінка). Могли б також виявитися і "викиди", тобто будинки, які могли б бути продані дорожче, з огляду на їхнє розташування і характеристики.
Фахівці з кадрів звичайно використовують процедури множинної регресії для визначення винагороди за адекватно виконану роботу. Можна визначити деяку кількість факторів або параметрів, таких, як "розмір відповідальності" (Resp) або "число підлеглих" (No_Super), які, як очікується, впливають на вартість роботи. Кадровий аналітик потім проводить дослідження розмірів окладів (Salary) серед порівнянних компаній на ринку, записуючи розмір платні та відповідні характеристики (тобто значення параметрів) по різних позиціях.
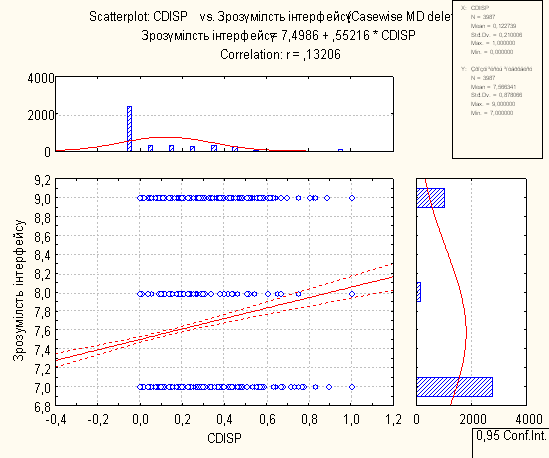
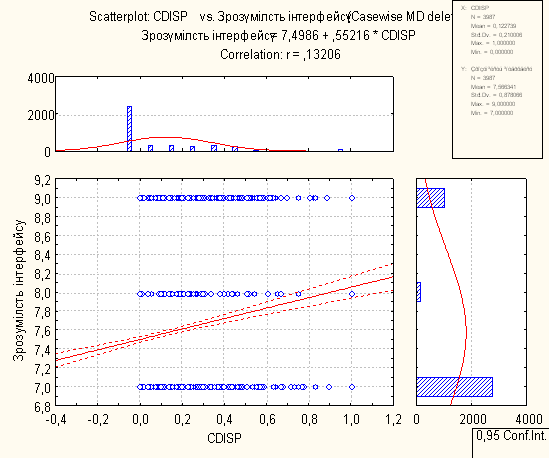
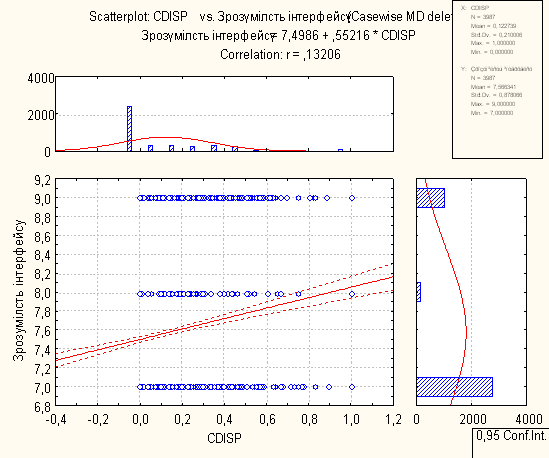
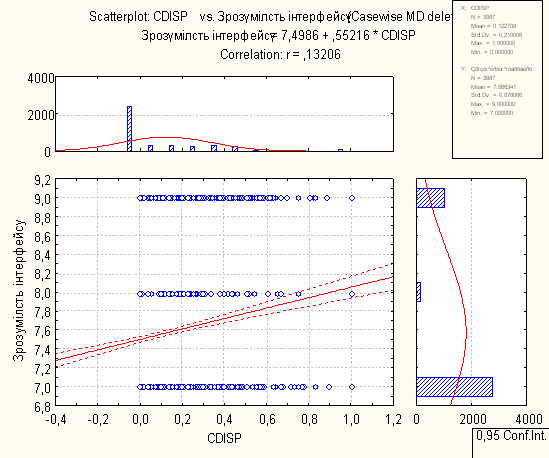
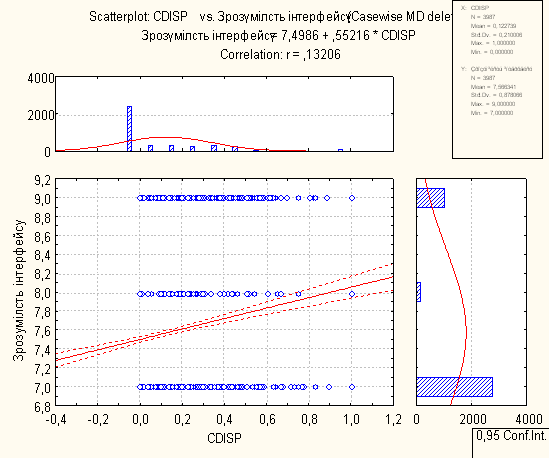
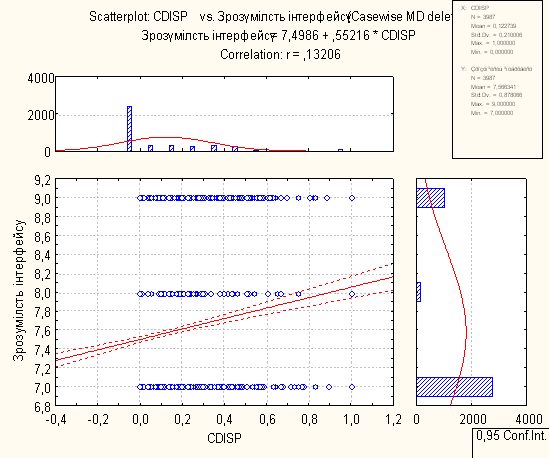

8. Висновки по регресійному аналізу
Для проведення регресійного аналізу був використаний пакет Statistica. За його допомогою було автоматично побудовано лінії регресії для пар метрика-експертна оцінка, визначено функції регресії.
На основі отриманих даних можна зробити наступні висновки:
- В основному присутня лінійна регресія
- З побудованих графіків можна зробити висновок, що переважна більшість пар «метрика-експертна» дуже слабо повязані.
9. Загальні висновки
При виконанні даної курсової роботи було засвоєно теоретичні та практичні навички. На основі отриманих даних по первинному статичному, кореляційному та регресійному аналізі можна зробити наступні висновки:
Було визначено:
· Метрики з нормальним розподілом
- CYCLO
- NOP
- FOUT
- AMW
- Ефективність(експертна оцінка)
· Метрики з ненормальним розподілом
- HIT
- BOvR
- CC
- CDISP
- ATFD
- Зрозумілість інтерфейсу(експертна оцінка)
Було оцінено значення отриманих коефіцієнтів кореляції
- Коефіцієнти кореляції не є дуже великим, що дає змогу сказати, що залежність між метриками та експертними оцінками, які досліджуються в даній курсовій роботі, не є значними.
На основі регресійного аналізу можна зробити висновок, що :
- В основному присутня лінійна регресія
- Переважна більшість пар «метрика-експертна» дуже слабо повязані.
Перепечатка материалов без ссылки на наш сайт запрещена