Курсовая работа: Распознавание графических символов
Курсовая работа: Распознавание графических символов
СОДЕРЖАНИЕ
ВВЕДЕНИЕ
1. ПОСТАНОВКА ЗАДАЧИ
2. ОПИСАНИЕ ИСПОЛЬЗОВАННЫХ АЛГОРИТМОВ
2.1 Алгоритм сегментации текста
2.2 Алгоритм распознавания слова. Персептрон
3. РАЗРАБОТКА И РЕАЛИЗАЦИЯ ПО
3.1 Архитектура программы
3.2 Интерфейс программы
3.3 Описание разработанных классов
4. ТЕСТИРОВАНИЕ ПО
4.1 Запуск приложения
ВЫВОДЫ
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
ПРИЛОЖЕНИЕ A ЛИСТИНГ ПРОГРАММЫ
ОПИСЬ ЛИСТОВ ГРАФИЧЕСКОЙ ЧАСТИ
В последние годы распознавание образов находит все большее применение в повседневной жизни. Распознавание речи и рукописного текста значительно упрощает взаимодействие человека с компьютером, распознавание печатного текста используется для перевода документов в электронную форму.
Реализация методов распознавания необходима в автоматизированных системах, предназначенных для использования в криминалистике, медицине, военном деле.
Особо следует отметить распознавание полноценных изображений. Область применения данного раздела многогранна. Например, на современных заводах контроль качества производимой продукции зачастую производят с использованием систем распознавания, которые отсеивают брак. Распознавание полноценных изображений применяется также на дорогах, для определения и распознавания номеров автомобилей, контроль их скорости. Обработка изображений актуальна и при анализе снимков из космоса и с самолётов. Таким образом, видно, что область применения распознавания изображений широка и многогранна и позволяет намного сократить и упростить рабочий процесс и вместе с тем повысить его качество. Однако, возможности интеллектуального анализа изображений с помощью компьютеров оставляют желать лучшего. Можно с уверенностью отметить лишь успехи в распознавании букв и цифр в документах и текстах, а также анализе изображений специального вида. Такая область как распознавание текстур, исследование в которой проводятся не одно десятилетие, пока не имеет универсальных методов.
Задачей распознавания изображений является применение методов, позволяющих либо получить некоторое описание изображения, поданного на вход системы, либо отнести это изображение к некоторому определенному классу. Процедура распознавания применяется к некоторому изображению и обеспечивает преобразование его в некоторое абстрактное описание: набор чисел, цепочку символов или граф. Последующая обработка такого описания позволяет отнести исходное изображение к одному из нескольких классов.
Но возникает ряд трудностей и проблем. Чаще всего это связано с тем, что изображения предъявляются на сложном фоне или изображения эталона и входные изображения отличаются положением в поле зрения, или входные изображения не совпадают с эталонами за счет случайных помех.
В данном курсовом проекте разработано приложение, позволяющие на изображении какого либо документа, либо просто текста находить слово "Указ". Входное изображение может быть любого размера, ориентация текста должна быть горизонтальной.
Приложение реализовано в среде программирования MS Visual Studio 2008 на языке C#. Платформа .Net дает широкий набор классов для работы с изображениями и обработки результатов.
1. ПОСТАНОВКА ЗАДАЧИ
Согласно заданию к курсовому проекту необходимо спроектировать приложение, реализованное на языке C# в среде разработки Microsoft Visual Studio 2008, реализующее распознавание слова "Указ" на изображении документа.
Исходные данные:
1. Растровое изображение документа.
2. Текст документа должен быть написан на белом фоне, черным шрифтом.
3. Шрифт текста не должен быть курсивным либо полужирным.
4. Размер изображения может быть любым.
5. Положение текста на изображении горизонтальное.
Приложение должно выполнять следующие задачи:
1. Загрузка изображения в приложение.
2. Сегментация текста на слова.
3. Распознавание среди слов слово "Указ".
Выходные данные:
1. Таблица найденных слов "Указ".
2. ОПИСАНИЕ ИСПОЛЬЗОВАННЫХ АЛГОРИТМОВ
2.1 Алгоритм сегментации текста
Процесс сегментации текста состоит из двух этапов: выделение строк текста и выделение слов в строках.
Поиск строк осуществляется путем просмотра пикселей изображения сверху вниз. При проходе запоминаются вертикальные координаты всех полностью белых полос на изображении (рисунок 2.1).

Рисунок 2.1 – Разбиение текста на строки
После нахождения всех белых горизонтальных полос анализируются их индексы. Для исключения соседних линий, строкой текста считается растр находящийся между двумя последовательными в списке, но не соседними белыми полосками.
Процесс поиска слов в строке заключается в анализировании вертикальных полос на изображении строки. При нахождении первой не полностью бело линии координата запоминается и считается начальной координатой слова, затем анализируются расстояния между буквами. При превышении некоторого порога слово "вырезается" из строки. Процесс продолжается до конца строки.
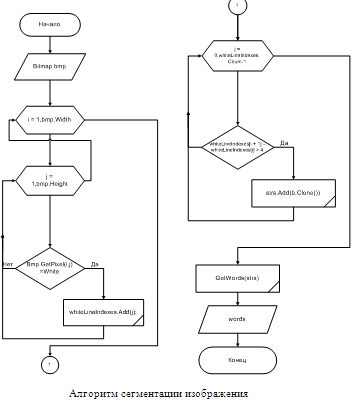
Алгоритм сегментации текста представлен в графической части
2.2 Алгоритм распознавания слова. Персептрон
Распознавание слова "Указ" в разработанном приложении, реализовано на базе персептрона. Алгоритм обучения персептрона – без учета правильности ответа. Персептрон построен по схеме "Несколько сумматоров". Общая схема персептрона представлена на рисунке 2.2
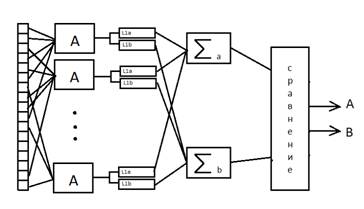
Рисунок 2.2 – Схема персептрона с несколькими сумматорами
Каждый А-элемент имеет несколько входов и один выход.
А-элементы производят алгебраическое суммирование сигналов, поступивших на их входы, и полученную сумму сравнивают с одинаковой для всех А-элементов величиной ϑ. Если сумма больше ϑ, А-элемент возбуждается и выдает на выходе сигнал, равный единице. Если сумма меньше ϑ, А-элемент остается невозбужденным и выходной его сигнал равен нулю. Таким образом, выходной сигнал j-го Α-элемента:
yj = ![]()

где величина rij принимает значение +1, если i -й рецептор подключен ко входу j-го Α-элемента со знаком плюс; и значение -1, если рецептор подключен со знаком минус, и значение 0, если i-ый рецептор к j-му Α-элементу не подключается (j = 1, 2, …, m, где m – число Α-элементов).
Выходные сигналы Α-элементов умножаются на переменные коэффициенты λj.
После умножения на λ выходные сигналы поступают на сумматоры Σ, количество которых также равно числу различаемых образов.
σ = ![]()
Предъявленный объект относится к тому образу, сумматор которого имеет наибольший сигнал.
В данной работе есть два распознаваемых класса условно из можно обозначить "Указ" и "Не указ". При обучении класса "Указ" на вход персептрона поступают изображения слова "Указ" написанное разными шрифтами. При обучении класса "Не указ", для повышения надежности работы персептрона, поступают те же изображения с текстом "Указ", но с инвертированными цветом.
В каждом такте персептрон отвечает на предъявленный ему объект возбуждением некоторых А-элементов. Обучение состоит в том, что коэффициенты λj возбужденных в данном такте А-элементов увеличиваются на некоторую величину (например на единицу), если в этом такте был предъявлен объект образа А, и уменьшается на эту же величину, если был предъявлен объект образа В.
3. РАЗРАБОТКА И РЕАЛИЗАЦИЯ ПО
3.1 Архитектура программы
Программа написана как проект Windows Forms Application, т.е. windows-приложение, графический интерфейс которого представлен формами и диалоговыми окнами. Структура разработанного проекта представлена на рисунке 3.1.
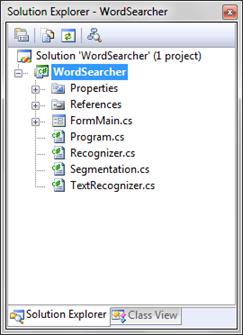
Рисунок 3.1 – Структура проекта
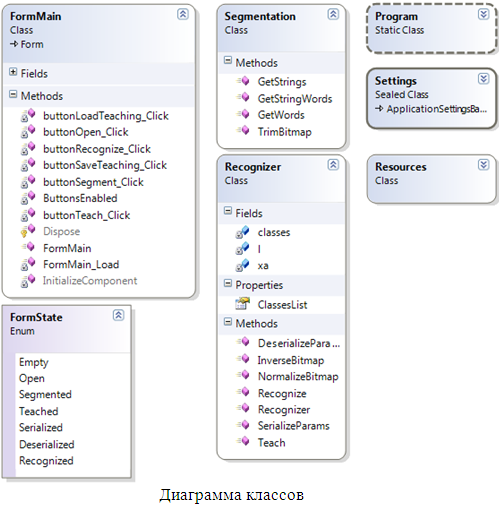
Приложение разработано на принципах ООП. Диаграмма разработанных классов представлена на рисунке 3.2
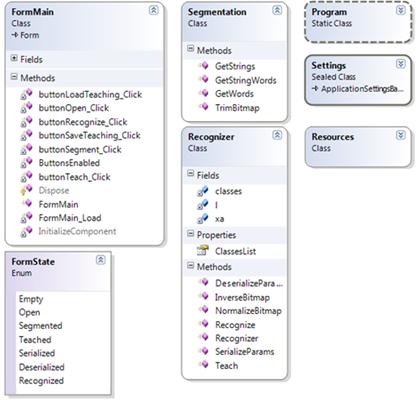
Рисунок 3.2 – Диаграмма классов приложения
Общая схема приложения в натации IDEF0 приведена на рисунке 3.3.
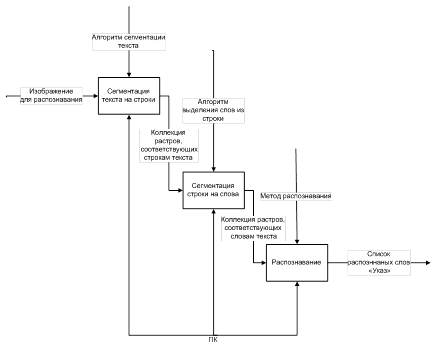
Рисунок 3.3 – Общая схема IDEF0 приложения
Пользовательский интерфейс представлен главным окном приложения, со всеми элементами управления, необходимыми для отображения и обработки информации. Главная форма в режиме проектирования показана на рисунке 3.4.
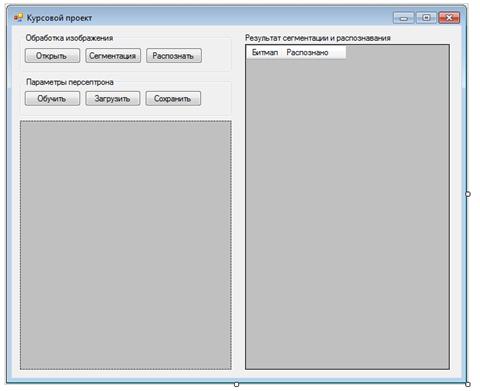
Рисунок 3.4 – Главная форма приложения в режиме проектирования
3.3 Описание разработанных классов
Ниже представлен перечень классов разработанных в приложение с кратким описанием их назначения и описанием основных методов.
Form1 – класс, описывающий главную форму приложения, содержит методы обработки событий от элементов управления. Содержит элементы управления для отображения исходного изображения, сегментов изображения и результатов распознавания.
Segmentation – описывает процесс сегментации изображения.
Методы:
public static List<Bitmap> GetStrings(Bitmap text) – выделение растров, соответствующих строкам текста;
public static List<Bitmap> GetStringWords(Bitmap str) – сегментирование одной строки на слова;
public static List <Bitmap> GetWords(Bitmap text) – выделение слов из всего текста;
public static Bitmap TrimBitmap(Bitmap bmp) – обрезка белых полей вокруг изображения на битмапе.
Recognizer – класс, реализующий персептрон для распознавания образов.
Методы :
public void Teach(Bitmap b, int classindex) – обучение персептрона;
public string Recognize(Bitmap b) – распознавание изображения b;
public void SerializeParams() – сохранение параметров персептрона на диске;
public void DeserializeParams() – чтение параметров персептрона с диска;
public static Bitmap NormalizeBitmap(Bitmap b, Size sz) – подгонка битмапа b по размеру sz. На выходе бинаризованное изображение размера sz;
public static Bitmap InverseBitmap(Bitmap b) – инверсия цвета изображения b.
4. ТЕСТИРОВАНИЕ ПО
Требования к установленному ПО:
- .Net Framework 3.5
Целью проведения испытаний является проверка работоспособности (надежности) программы при различных условиях ее функционирования и настройках. Для демонстрации работоспособности программы необходимо провести ряд испытаний с различными начальными условиями.
Тестовые примеры выполнялись в среде операционной системы Windows 7 Ultimate при использовании процессора AMD Athlon 3600+ 1.9 ГГц, 1 Гб RAM и разрешении экрана 1280x1024.
Приложение подверглось критическому и углубленному тестированию.
При проведении критического тестирования не было выявлено ошибок и некорректной работы приложения.
4.1 Запуск приложения
Для запуска приложения необходимо запустить исполняемый файл WordSearcher.exe. Окно приложения после запуска показано на рисунке 3.4
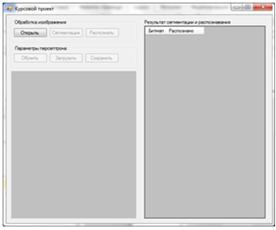
Рисунок 3.4 – Главное окно приложения
Для начала работы необходимо загрузить исходное изображение, для чего необходимо нажать кнопку "Открыть". В диалоге выбора файла необходимо выбрать изображение. Окно программы после открытия исходного изображения представлено на рисунке 3.5
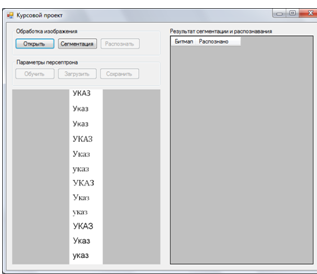
Рисунок 3.5 – Окно программы с открытым изображением
После открытия изображения становится активным кнопка "Сегментация", после нажатия на которую, текст на изображении разбивается на слова.
Результат сегментации представлен на рисунке 3.6.
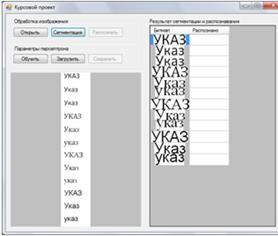
Рисунок 3.6 – Результат сегментации
Перед непосредственным распознаванием текста необходимо произвести обучение персептрона, нажав кнопку "обучить", либо загрузить ранее сохраненные параметры, нажав кнопку "загрузить". Обучение персептрона осуществляется изображением содержащим слово "Указ", написанное разными шрифтами. После обучения, можно сохранить параметры персептрона в файл, нажав "сохранить", и прочитать их при следующем распознавании.
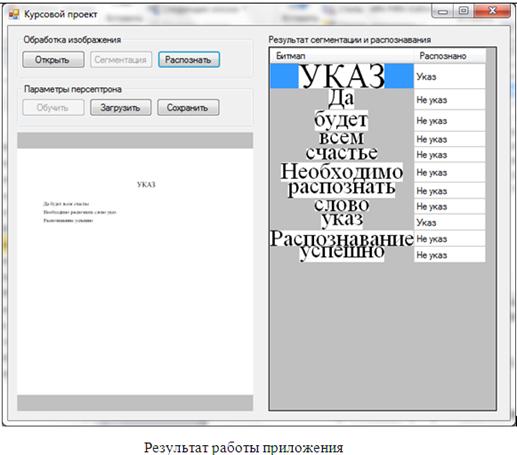
После обучения, либо загрузки параметров персептрона, можно производить распознавание изображений. Результат распознавания показан на рисунке 3.7.
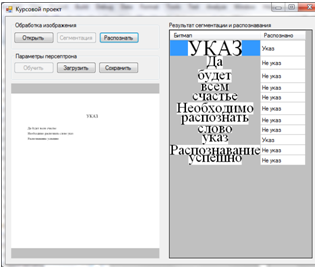
Рисунок 3.7 – Результат распознавания
При углубленном тестировании также не было найдено ошибок. Интерфейс программы разработан таким образом, что пользователю на каждом этапе обработки изображения может выполнить только определенные действия, что значительно снижает риск появления ошибок выполнения.
Результат работы программы при загрузке не файла изображения представлен на рисунке 3.8.
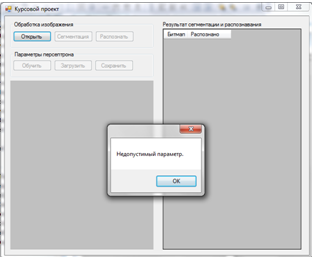
Рисунок 3.8 – Результат работы приложения при неверно формате файла
ВЫВОДЫ
В результате выполнения данного курсового проекта было разработано приложение, позволяющее распознавать слово "Указ" в тексте на изображении. Размеры изображения и шрифта текста может быть практически любым, что дает гибкие возможности для применения приложения.
Для распознавания применяется персептрон. Качество распознавания изображения зависит от количества предложенных образов для обучения и количество А-элементов. Количество поддерживаемых шрифтов зависит от шрифтов, которым написаны слова на изображениях для обучения.
Перед непосредственным распознаванием, как правило, необходимо выполнять сегментацию изображения. Сегментация является неотъемлемой частью при распознавании образов, в общем случае, и непосредственно в данном проекте, так как ее результатом являются изображения, содержащие только необходимые для распознания объекты (слова текста).
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
1. Microsoft Developer Network (MSDN) [Электрон. ресурс]. ‑ Режим доступа: http://msdn.ru/
2. Ковалева И.Л., "Алгоритмы обработки изображений", БНТУ, 2007
ПРИЛОЖЕНИЕ A
Небольшой мануал по проге:
- Текст должен быть черным по белому
- Картинки для теста есть в архиве.
- Ориентация текста не под углом.
- Размер картинки желательно не меньше чем, те, что лежат в архиве, потому что при маленьком изображении плохо распознается из-за сливания пикселей.
- Распознавание персептроном с несколькими сумматорами и алгоритмом обучения без учета правильности ответа (она может это спросить=)
- Для обучения персептрона надо открыть изображение "Картинка для обучения.png" из папки "тестовые изображения" или создать аналогичную самостоятельно и открыть ее. Потом нажать "сегментация", Потом "Обучить", можно сохранить обучение, нажав "сохранить". Теперь можно открывать изображение, которое будет распознаваться. Для распознавания надо нажать "сегментация", потом "распознать".
- Если проводилось сохранение обучения, то можно не обучать. Для распознавания в таком случае надо делать следующие: открываешь распознаваемое изображение, нажимаешь "Сегментация", нажимаешь "загрузить", нажимаешь "распознать".
- В записке в графической части нужно вставить некоторые свои данные, я их отметил красным.
- путь к EXE-шнику: \WordSearcher\WordSearcher\bin\Debug\ WordSearcher.exe
Если будут какие-то баги или вопросы, сообщай - исправлю.
С уважением, Свирко Юрий
Mail: sv1r4.sd@gmail.com
Phone: 8-033-63-123-60
ЛИСТИНГ ПРОГРАММЫ
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Windows.Forms;
namespace WordSearcher
{
public partial class FormMain : Form
{
/// <summary>
/// Флаг разрешения распознавания
/// </summary>
bool enableRecognize = false;
/// <summary>
/// Размер битмапа со словом "Указ"
/// к этому размеру подгоняются все отсалдьные распознаваемые битмапы
/// </summary>
private static Size imSize = new Size(65, 25);
/// <summary>
/// Состояние формы
/// </summary>
private FormState formState = FormState.Empty;
/// <summary>
/// Масив битмапов сос словами текста
/// </summary>
private List<Bitmap> words;
/// <summary>
/// Объект класса для распознавания(персептрон)
/// </summary>
private Recognizer r = new Recognizer(imSize, 750, 2);
/// <summary>
/// Метод для делания активными неактивными кнопок управления
/// в зависимости от этапа обработк изображения
/// </summary>
/// <param name="fs">текущее состояние</param>
private void ButtonsEnabled(FormState fs)
{
formState = fs;
switch (fs)
{
case FormState.Empty:
buttonOpen.Enabled = true;
buttonSegment.Enabled = false;
buttonRecognize.Enabled = false;
buttonTeach.Enabled = false;
buttonLoadTeaching.Enabled = false;
buttonSaveTeaching.Enabled = false;
pictureBoxMain.Image = null;
dataGridViewSegments.Rows.Clear();
break;
case FormState.Open:
buttonOpen.Enabled = true;
buttonSegment.Enabled = true;
buttonRecognize.Enabled = false;
buttonTeach.Enabled = false;
buttonLoadTeaching.Enabled = false;
buttonSaveTeaching.Enabled = false;
dataGridViewSegments.Rows.Clear();
break;
case FormState.Segmented:
buttonOpen.Enabled = true;
buttonSegment.Enabled = true;
if (enableRecognize)
buttonRecognize.Enabled = true;
else
buttonRecognize.Enabled = false;
buttonTeach.Enabled = true;
buttonLoadTeaching.Enabled = true;
buttonSaveTeaching.Enabled = false;
break;
case FormState.Teached:
buttonOpen.Enabled = true;
buttonSegment.Enabled = false;
buttonRecognize.Enabled = true;
buttonTeach.Enabled = false;
buttonLoadTeaching.Enabled = false;
buttonSaveTeaching.Enabled = true;
enableRecognize = true;
break;
case FormState.Deserialized:
buttonOpen.Enabled = true;
buttonSegment.Enabled = false;
buttonRecognize.Enabled = true;
buttonTeach.Enabled = false;
buttonLoadTeaching.Enabled = false;
buttonSaveTeaching.Enabled = true;
enableRecognize = true;
break;
case FormState.Recognized:
buttonOpen.Enabled = true;
buttonSegment.Enabled = false;
buttonRecognize.Enabled = true;
buttonTeach.Enabled = false;
buttonLoadTeaching.Enabled = true;
buttonSaveTeaching.Enabled = true;
break;
}
}
public FormMain()
{
InitializeComponent();
}
private void buttonOpen_Click(object sender, EventArgs e)
{
try
{
Bitmap b;
if (openFileDialog1.ShowDialog() == DialogResult.OK)
pictureBoxMain.Image = b;
else
{
this.ButtonsEnabled(FormState.Empty);
}
}
catch (Exception ex)
{
MessageBox.Show(ex.Message);
}
}
private void buttonSegment_Click(object sender, EventArgs e)
{
//Получаем набор битмапов соответствующих словам текста
words = Segmentation.GetWords((Bitmap)pictureBoxMain.Image);
dataGridViewSegments.RowCount = words.Count;
int i =0;
//Перебираем слов и отображаем в таблице
foreach (Bitmap word in words)
{
dataGridViewSegments.Rows[i].Cells[0].Value = word;
i++;
}
ButtonsEnabled(FormState.Segmented);
}
private void buttonRecognize_Click(object sender, EventArgs e)
{
int i = 0;
foreach (Bitmap word in words)
{
dataGridViewSegments.Rows[i].Cells[1].Value = r.Recognize(Recognizer.NormalizeBitmap(word,imSize));
i++;
}
ButtonsEnabled(FormState.Recognized);
}
private void buttonTeach_Click(object sender, EventArgs e)
{
//Перебираем слова и обучаем ими
//т.к. класса для распознаваня два то
//первый класс обучаем просто изображение слова
//а второй обучаем противопорложным изображение(т.е инвертируем цвета исходного изображения)
for (int i = 0; i < 5; i++)
{
foreach (Bitmap word in words)
{
r.Teach(Recognizer.NormalizeBitmap(word, imSize), 0);
r.Teach(Recognizer.InverseBitmap(Recognizer.NormalizeBitmap(word, imSize)), 1);
}
}
ButtonsEnabled(FormState.Teached);
}
private void buttonSaveTeaching_Click(object sender, EventArgs e)
{
r.SerializeParams();
ButtonsEnabled(FormState.Serialized);
}
private void buttonLoadTeaching_Click(object sender, EventArgs e)
{
r.DeserializeParams();
ButtonsEnabled(FormState.Deserialized);
}
private void FormMain_Load(object sender, EventArgs e)
{
this.ButtonsEnabled(FormState.Empty);
}
}
// <summary>
/// Состояния изображения
/// </summary>
enum FormState
{
/// <summary>
/// изображение не открыто
/// </summary>
Empty,
/// <summary>
/// Изображение открыто
/// </summary>
Open,
/// <summary>
/// Сегментировано
/// </summary>
Segmented,
/// <summary>
/// Персептрон обучен
/// </summary>
Teached,
/// <summary>
/// Параметры персептрона сохранены
/// </summary>
Serialized,
/// <summary>
/// Параметры персептрона загружены
/// </summary>
Deserialized,
/// <summary>
/// Распознано
/// </summary>
Recognized
}
}
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Drawing;
using System.Windows.Forms;
using System.IO;
using System.Runtime.Serialization.Formatters.Binary;
namespace WordSearcher
{
/// <summary>
/// Реализует распозноание изображений
/// на базе персептрона
/// </summary>
class Recognizer
{
/// <summary>
/// матрица знаков входов персептрона
/// </summary>
private int[,] xa;
/// <summary>
/// Массив лямд
/// </summary>
private int[,] l;
/// <summary>
/// Массив имен классов
/// </summary>
private string[] classes = {"Указ",
"Не указ"};
/// <summary>
/// Массив имен классов
/// </summary>
public string[] ClassesList
{
get { return classes; }
}
/// <summary>
/// Инициализирует xa-матрицу
/// </summary>
/// <param name="sz">размер изображения</param>
/// <param name="aCount">количесвто а-элементов</param>
/// <param name="lCount">количесвто классов</param>
public Recognizer(Size sz, int aCount, int lCount)
{
Random r = new Random();
//Создание матрцы ха
xa = new int[sz.Height * sz.Width, aCount];
//Создание матрицы лямд
l = new int[lCount,aCount];
//Первоначальная
//иницализация лямд еденицами
for (int i = 0; i < l.GetLength(0); i++)
{
for (int j = 0; j < l.GetLength(1); j++)
{
l[i, j] = 1;
}
}
//заполнение матрицы
//для каждого рецептора(строчки)
//назначаетя только один а-элемент(столбец) со знаком + или -
for (int i = 0; i < xa.GetLength(0); i++)
{
xa[i, r.Next(aCount)] = (int)Math.Pow(-1, r.Next(1, 3));
}
}
/// <summary>
/// Обучение персептрона
/// </summary>
/// <param name="b">битмап для обучения</param>
/// <param name="classindex">имя класса к ккоторому относиться изображение</param>
public void Teach(Bitmap b, int classindex)
{
int[] x = new int[b.Height * b.Width];
int k = 0;
//Инициализация входных рецепторов
for (int i = 0; i < b.Width; i++)
{
for (int j = 0; j < b.Height; j++)
{
if (b.GetPixel(i, j) == Color.FromArgb(0, 0, 0))
x[k] = 1;
k++;
}
}
//Вектор сумм рецепторов
int[] sumx = new int[xa.GetLength(1)];
//Вектор выходов А-элементов
int[] outa = new int[xa.GetLength(1)];
//суммирование сигналов от рецепторов
for (int i = 0; i < xa.GetLength(1); i++)
{
for (int j = 0; j < xa.GetLength(0); j++)
{
sumx[i] += x[j] * xa[j, i];
}
//Если сумма больше нуля выход а элемента 1
if (sumx[i] > 0)
outa[i] = 1;
}
//изменение коэфициетов лямда
for (int i = 0; i < outa.Length; i++)
{
//Если а-элемент возбужден то изменяем лямды
if (outa[i] == 1)
{
//перебор всех классов
for (int j = 0; j < l.GetLength(0); j++)
{
//Увеличение на 1 лямд для класса который обучается
//и уменьшение для всех осатльных
if (classindex == j)
l[j, i]++;
else
l[j, i]--;
}
}
}
}
/// <summary>
/// Распознавание изобржения
/// </summary>
/// <param name="b">битмап изображения</param>
/// <returns>имя класса к которому отнесено изображение</returns>
public string Recognize(Bitmap b)
{
int[] x = new int[b.Height * b.Width];
int k = 0;
//Инициализация входных рецепторов
for (int i = 0; i < b.Width; i++)
{
for (int j = 0; j < b.Height; j++)
{
if (b.GetPixel(i, j) == Color.FromArgb(0, 0, 0))
x[k] = 1;
k++;
}
}
//Вектор суммрецепторов
int[] sumx = new int[xa.GetLength(1)];
//Вектор выходов А-элементов
int[] outa = new int[xa.GetLength(1)];
//суммирование сигналов от рецепторов
for (int i = 0; i < xa.GetLength(1); i++)
{
for (int j = 0; j < xa.GetLength(0); j++)
{
sumx[i] += x[j] * xa[j, i];
}
//Если сумма больше нуля выход а элемента 1
if (sumx[i] > 0)
outa[i] = 1;
}
//Создание масива значений сумматоров
//каждый для отдельного класса
int[] sum = new int[l.GetLength(0)];
//Нахождение значений сумматоров для каждого класса
for (int i = 0; i < sum.Length; i++)
{
for (int j = 0; j < xa.GetLength(1); j++)
{
sum[i] += outa[j] * l[i, j];
}
}
//нахождение максимального значения сумматор
//именно оно соответствует распознанному классу
int max = sum[0];
int maxindex = 0;
for (int i = 1; i < sum.Length; i++)
{
if (max < sum[i])
{
max = sum[i];
maxindex = i;
}
}
//Возвращается имя класса с максимальным значением сумматора
return classes[maxindex];
}
/// <summary>
/// Сериализация массива лямд(сохранение в файл) для сохранения обученяи персептрона
/// </summary>
public void SerializeParams()
{
try
{
BinaryFormatter bf = new BinaryFormatter();
FileStream fs = new FileStream("l.dat", FileMode.Create);
bf.Serialize(fs, l);
fs.Close();
bf = new BinaryFormatter();
fs = new FileStream("xa.dat", FileMode.Create);
bf.Serialize(fs, xa);
fs.Close();
}
catch (Exception ex)
{
MessageBox.Show(ex.Message);
}
}
/// <summary>
/// Десериализация массива лямд(чтение из файла)
/// </summary>
public void DeserializeParams()
{
try
{
BinaryFormatter bf = new BinaryFormatter();
FileStream fs = new FileStream("l.dat", FileMode.Open);
l = (int[,])bf.Deserialize(fs);
fs.Close();
bf = new BinaryFormatter();
fs = new FileStream("xa.dat", FileMode.Open);
xa = (int[,])bf.Deserialize(fs);
fs.Close();
}
catch (Exception ex)
{
MessageBox.Show(ex.Message);
}
}
/// <summary>
/// Подгонка битмапа по размеру и его бинаризация
/// </summary>
/// <param name="b">входной битмап</param>
/// <param name="sz">новый размер битмапа</param>
/// <returns>нормализованный битмап</returns>
public static Bitmap NormalizeBitmap(Bitmap b, Size sz)
{
//Подгонка размера
Bitmap inImg = new Bitmap(b, sz);
//Создание выходного битмапа на основе подогнанного
Bitmap outImg = new Bitmap(inImg);
//находим среднее значение яркости
int sum = 0;
for (int i = 0; i < outImg.Width; i++)
{
for (int j = 0; j < outImg.Height; j++)
{
Color cl = ((Bitmap)inImg).GetPixel(i,j);
sum += (cl.R + cl.G + cl.B) / 3;
}
}
int sredn = sum / (inImg.Width * inImg.Height);
//Просматриваем изображнеи и бинаризуем его
for (int i = 0; i < outImg.Width; i++)
{
for (int j = 0; j < outImg.Height; j++)
{
Color cl = ((Bitmap)inImg).GetPixel(i,j);
int gray = (cl.R + cl.G + cl.B) / 3;
if (gray > sredn)
outImg.SetPixel(i, j, Color.FromArgb(255, 255, 255));
else
outImg.SetPixel(i, j, Color.FromArgb(0, 0, 0));
}
}
return outImg;
}
/// <summary>
/// Инверсия цвета битмапа
/// </summary>
/// <param name="b"></param>
/// <returns></returns>
public static Bitmap InverseBitmap(Bitmap b)
{
Bitmap outImg = new Bitmap(b.Width, b.Height);
for (int i = 0; i < b.Width; i++)
{
for (int j = 0; j < b.Height; j++)
{
Color c = b.GetPixel(i,j);
outImg.SetPixel(i, j, Color.FromArgb(255 - c.R, 255 - c.G, 255 - c.B));
}
}
return outImg;
}
}
}
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Drawing;
namespace WordSearcher
{
class Segmentation
{
/// <summary>
/// Разбиение битмапа с текстоми на строки
/// </summary>
/// <param name="b">исходный битмап</param>
/// <returns>коллекция строк</returns>
public static List<Bitmap> GetStrings(Bitmap text)
{
List<Bitmap> strs = new List<Bitmap>();
List<int> whiteLineIndexes = new List<int>();
//Находим все белые горзонатльные линии на ихображении
//и запоминаем их индексы
for (int j = 0; j < text.Height; j++)
{
bool whiteLineFound = true;
for (int i = 0; i < text.Width; i++)
{
if (text.GetPixel(i, j) != Color.FromArgb(255, 255, 255))
{
whiteLineFound = false;
break;
}
}
if (whiteLineFound)
whiteLineIndexes.Add(j);
}
//Выделение строк между белыми несоседними линиями
for (int i = 0; i < whiteLineIndexes.Count-1; i++)
{
if (whiteLineIndexes[i + 1] - whiteLineIndexes[i] > 4)
{
strs.Add(text.Clone(
new Rectangle(
0,
whiteLineIndexes[i],
text.Width,
whiteLineIndexes[i + 1] - whiteLineIndexes[i]+1),
System.Drawing.Imaging.PixelFormat.Format24bppRgb));
}
}
return strs;
}
/// <summary>
/// Получить список слов отдельной строки
/// </summary>
/// <param name="str">битмап со строкой текста</param>
/// <returns>спсиок слов строки</returns>
public static List<Bitmap> GetStringWords(Bitmap str)
{
List<Bitmap> words = new List<Bitmap>();
List<int> whiteLineIndexes = new List<int>();
//Находим все белые вертикальные линии на изображении
//и запоминаем их индексы
for (int i = 0; i < str.Width; i++)
{
bool whiteLineFound = true;
for (int j = 0; j < str.Height; j++)
{
if (str.GetPixel(i, j).R < 100)
{
whiteLineFound = false;
break;
}
}
if (whiteLineFound)
whiteLineIndexes.Add(i);
}
//Ширина пробела
int spaceWidth = 0;
int sum = 0;
int n = 0;
//Вычисление ширины пробела
for (int i = 0; i < whiteLineIndexes.Count - 1; i++)
{
int d = whiteLineIndexes[i + 1] - whiteLineIndexes[i];
if (d > 1)
{
sum += d;
n++;
}
}
//Ширина пробела необходимо при дальнейшем выделении слов
//коэф. подобран вручную
spaceWidth = (int)Math.Round(sum * 0.45 / n + 0.1);
//начальная координата слова
int wordBegin = 0;
//конечная координат слова
int wordEnd = 0;
//флаг указывающий на то найденно ли начало слова или нет
//перволдится обратно в фолс после нахождения конца слова
bool wordFound = false;
//Счетчик ширины белой полоски
int whiteWidth = 0;
//Выделение слов
for (int i = 0; i < whiteLineIndexes.Count - 1; i++)
{
//если линии не соседние и флаг wordFound фолс т.е.
//слово еще не найдено
//запоминаем координату певрой линии это будет
//координатой началом слова
if ((whiteLineIndexes[i + 1] - whiteLineIndexes[i] > 1) &&
!wordFound)
{
//обнуление счетчика идущих подряд белыхз линий
whiteWidth = 0;
//флаг найденного слова в тру
wordFound = true;
//инициализируем начальную координату слова
wordBegin = whiteLineIndexes[i];
}
//инициализируем конечную координату слова
//если найдены не сосдение линии
//но не обрезаем битмап и не добавлям его в коллекцию
//т.к. необходисмо зделать проверку на ширину пробела
if ((whiteLineIndexes[i + 1] - whiteLineIndexes[i] > 1) &&
wordFound)
{
whiteWidth = 0;
wordEnd = whiteLineIndexes[i + 1];
}
//Если найденны соседние белые линии
//инкремируем счетчик белых линий и сравниваем ширину идущих подрд белых линий
//с ранее высчитаной средней шириной пробела
if (whiteLineIndexes[i + 1] - whiteLineIndexes[i] == 1)
{
whiteWidth++;
if ((whiteWidth >= spaceWidth) &&
(wordEnd - wordBegin > 1))
{
//Обрезаем и добавляем слово в коллекцию
words.Add(TrimBitmap(
str.Clone(
new Rectangle(
wordBegin,
0,
wordEnd - wordBegin + 1,
str.Height),
System.Drawing.Imaging.PixelFormat.Format24bppRgb)
)
);
//обнуляем счетчики
//и флаги
whiteWidth = 0;
wordFound = false;
wordBegin = 0;
wordEnd = 0;
}
}
}
return words;
}
/// <summary>
/// Получить битмапы всех слов в тексте
/// </summary>
/// <param name="text">битмап с текстом</param>
/// <returns>коллекция всех слов в тексте</returns>
public static List<Bitmap> GetWords(Bitmap text)
{
List<Bitmap> strs = GetStrings(text);
List<Bitmap> words = new List<Bitmap>();
foreach (Bitmap str in strs)
{
foreach (Bitmap word in GetStringWords(str))
{
words.Add(word);
}
}
return words;
}
/// <summary>
/// Обрезка белых полей вокруг изображения на битмапе
/// </summary>
/// <param name="bmp"></param>
/// <returns></returns>
public static Bitmap TrimBitmap(Bitmap bmp)
{
int left = 0;
int right = 0;
int top = 0;
int bottom = 0;
bool go = true;
//проход сверху
for (int j = 0; (j < bmp.Height) && go; j++)
{
for (int i = 0; (i < bmp.Width) && go; i++)
{
if (bmp.GetPixel(i, j) != Color.FromArgb(255, 255, 255))
{
go = false;
top = j;
}
}
}
go = true;
//проход снизу
for (int j = bmp.Height - 1; (j >= 0) && go; j--)
{
for (int i = 0; (i < bmp.Width) && go; i++)
{
if (bmp.GetPixel(i, j) != Color.FromArgb(255, 255, 255))
{
go = false;
bottom = j;
}
}
}
go = true;
//проход слева
for (int i = 0; (i < bmp.Width) && go; i++)
{
for (int j = 0; (j < bmp.Height) && go; j++)
{
if (bmp.GetPixel(i, j) != Color.FromArgb(255, 255, 255))
{
go = false;
left = i;
}
}
}
go = true;
//проход спарва
for (int i = bmp.Width - 1; (i >= 0) && go; i--)
{
for (int j = 0; (j < bmp.Height) && go; j++)
{
if (bmp.GetPixel(i, j) != Color.FromArgb(255, 255, 255))
{
go = false;
right = i;
}
}
}
return bmp.Clone(new Rectangle(left, top, right - left + 1, bottom - top + 1), System.Drawing.Imaging.PixelFormat.Format24bppRgb);
}
}
}
ОПИСЬ ЛИСТОВ ГРАФИЧЕСКОЙ ЧАСТИ
Лист 1 – Схема приложения
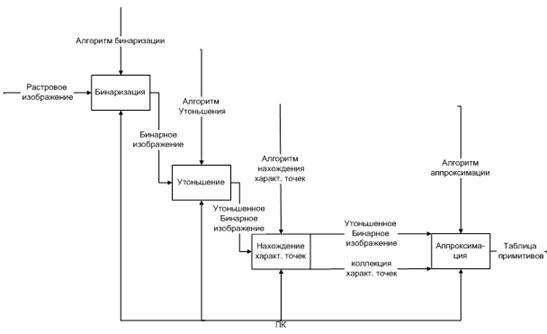
Функциональная схема приложения
Лист 2 – Диаграмма классов
Лист 3 – Результаты работы программы.
Лист 4 – Схема алгоритма сегментации текста.
Перепечатка материалов без ссылки на наш сайт запрещена